|
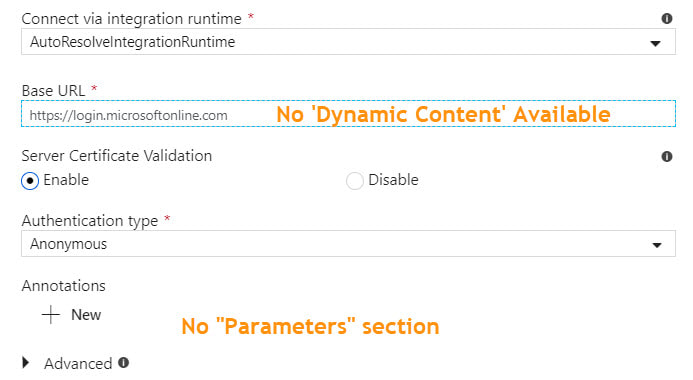
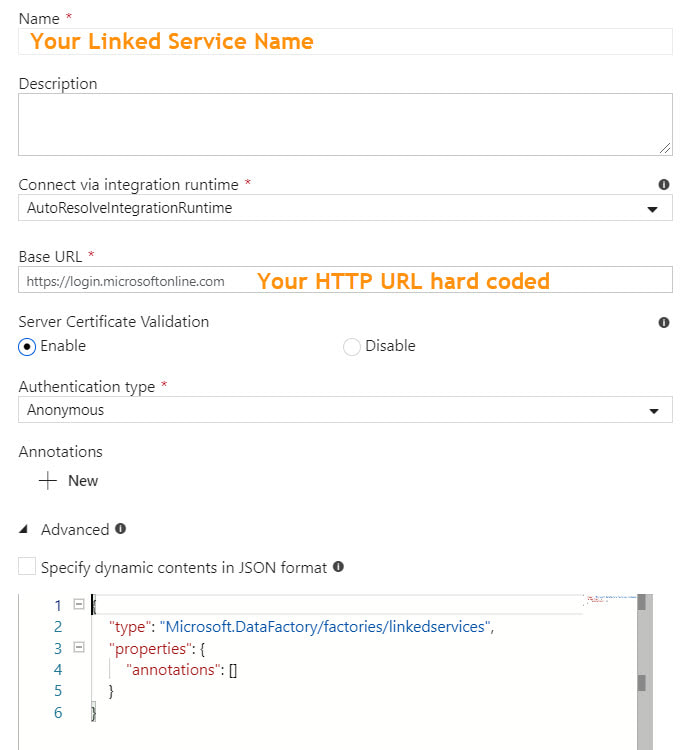
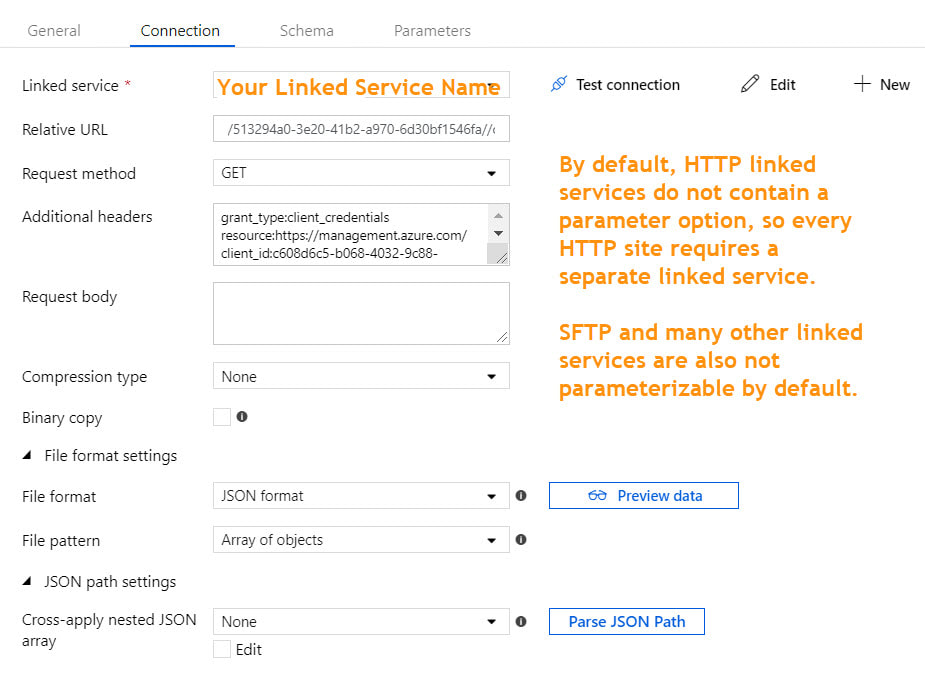
There are several linked service types that do not have built-in dynamic content in which it is possible to reference a parameter. For example, if your linked service is an Azure SQL Database, you can parameterize the server name, database name, user name, and Azure Key Vault secret name. This allows for one linked service for all Azure SQL Databases. However, if your linked service is HTTP or SFTP (or many others), there is no "dynamic content" option for key properties. This forces one linked service and one dataset for every HTTP Base URL or one linked service and dataset for every SFTP host, port and user name.
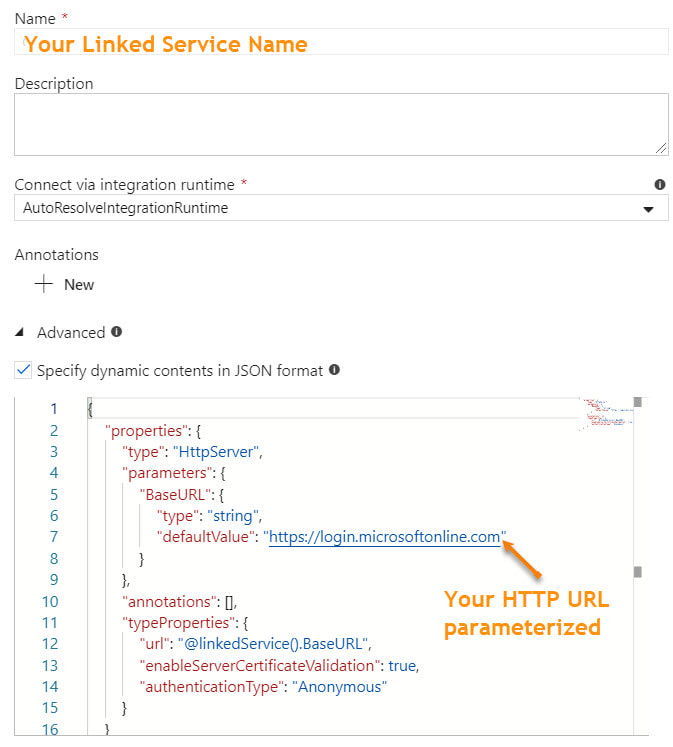
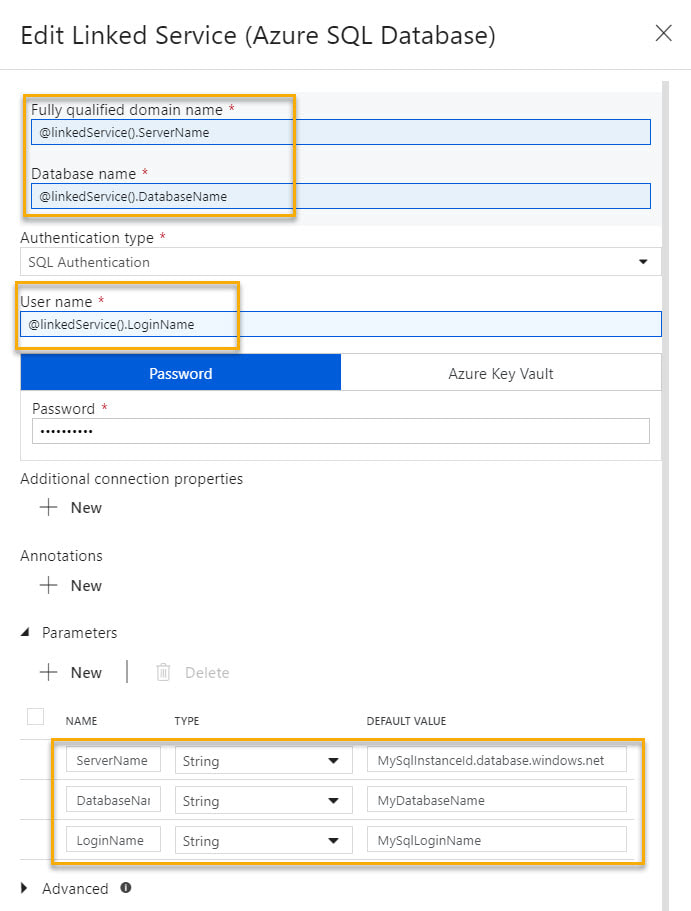
Microsoft has provided a nice solution to this problem, and it lies in the "Advanced" section of each linked service. Understanding that it is JSON syntax that sits behind the GUI of linked services, to add parameters to a linked service, we can manually modify the JSON. At this point and if this blog post were a Microsoft Doc, most of us would be scrolling down and saying, "Just show me the JSON!". Knowing this, here you go -->
***************************************************************************************************************************
Now the question is, "How does the dataset handle this customized linked service?" I was very pleased to find that the integration of the custom JSON into a dataset was seamless.
One of the nice things about Azure Data Factory (ADFv2) is the level of parameterization now available. Until all linked service properties accept dynamic content by default, this is a nice workaround.
8 Comments
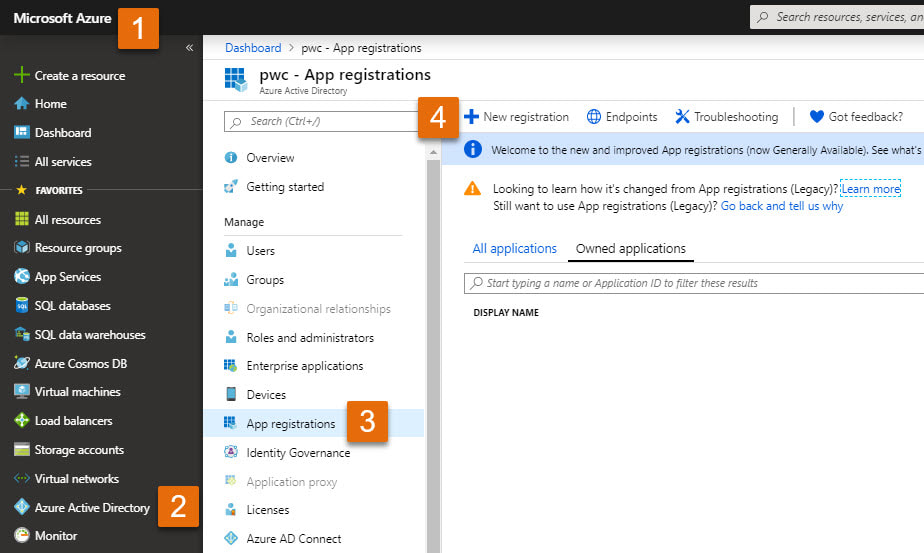
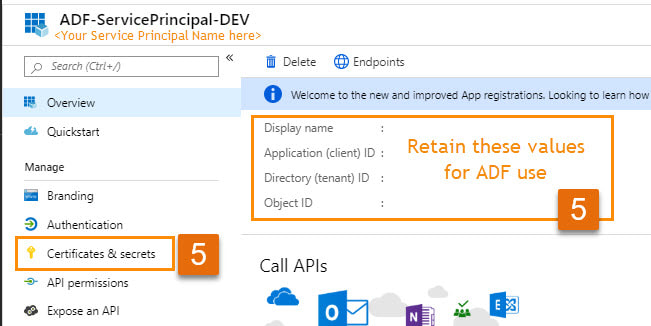
Previously I published a Quick Start Guide for avoiding concurrent pipeline executions. That was blog post 1 of 2, and I wrote it for developers familiar with Azure, especially Azure AD service principals and ADF web activities. For everyone else, I would like to provide more tips and screen prints, because if your brain works anything like mine, I put A and B together much better with a picture. When I first started with ADF and accessed Microsoft Docs, I struggled with connecting the JSON examples provided with the ADF activity UIs (user interfaces). If you had been near, you may have heard me sputtering, "what? What? WHAT??!" Enough said. This blob post will follow the same step numbers as blog post 1, so if you started with the Quick Start Guide, you can find detail for those same steps right here. Step #1: Create a service principal and record the client Id, client secret, and tenant Id for future use. When you query the ADF log, you have to impersonate someone. In ADF you do this through an Azure AD (Active Directory) application, also called a service principal. You then must give this service principal permissions in the Data Factory. If you have worked with SSIS, this is a similar concept. You run SSIS scheduled jobs as <some AD account> and that account must have permissions to your source and destinations.
Step #2: Create a file or SQL Server table to hold your environment properties. This can be a text file, SQL Server table, Cosmos DB document -- any source that can be accessed by ADF in a Lookup activity will work.
 Step #3: Create a new pipeline with parameters and variables.
Step #4: Add a Lookup activity to the pipeline named "Get Environment Properties" If you used my SQL Server metadata script above, your lookup activity properties will look similar to the next screen print. To read the data values stored in memory, ADF syntax would be @activity('Get environment Properties').output.firstRow.YourColumnName. 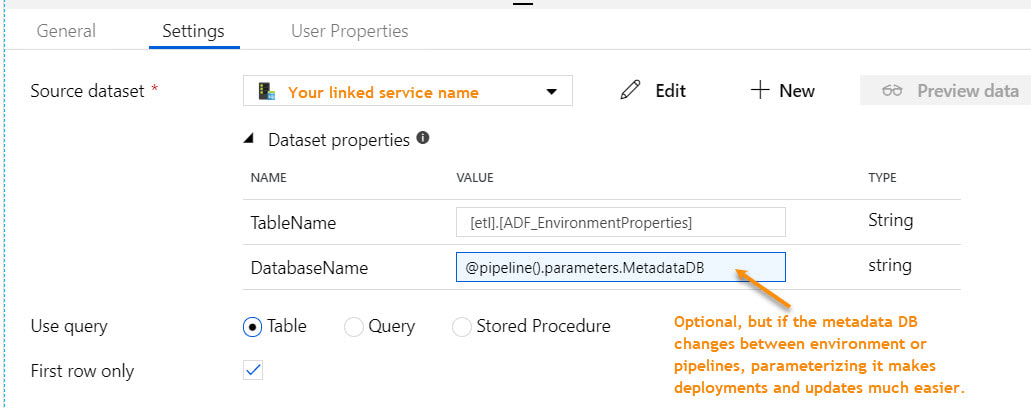
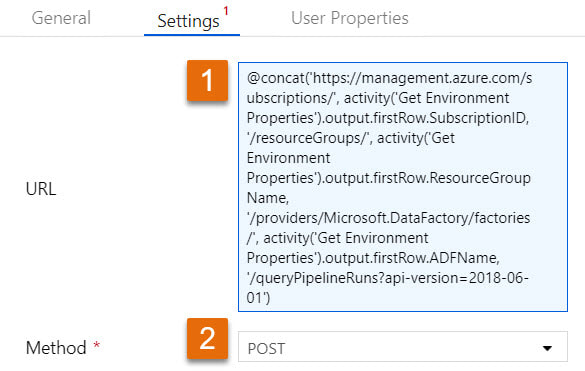
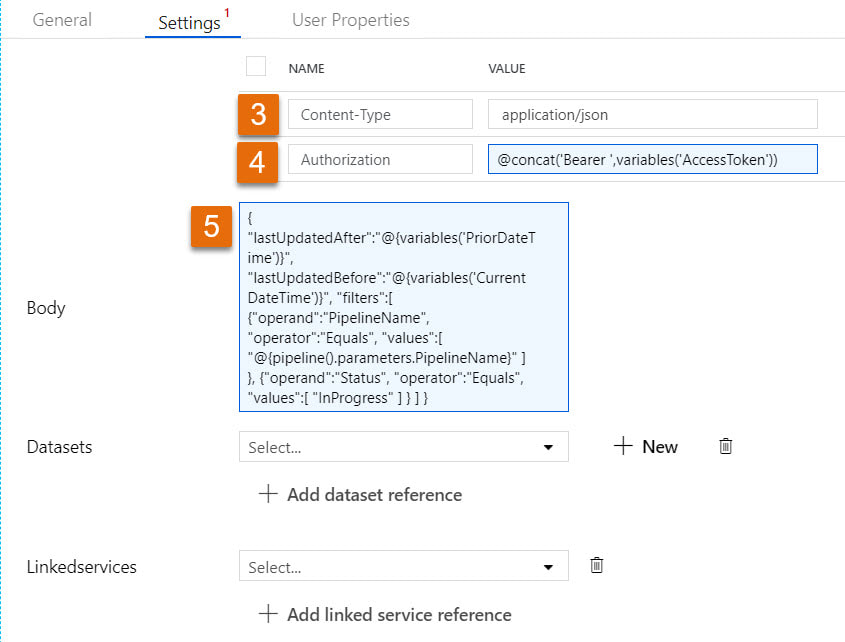
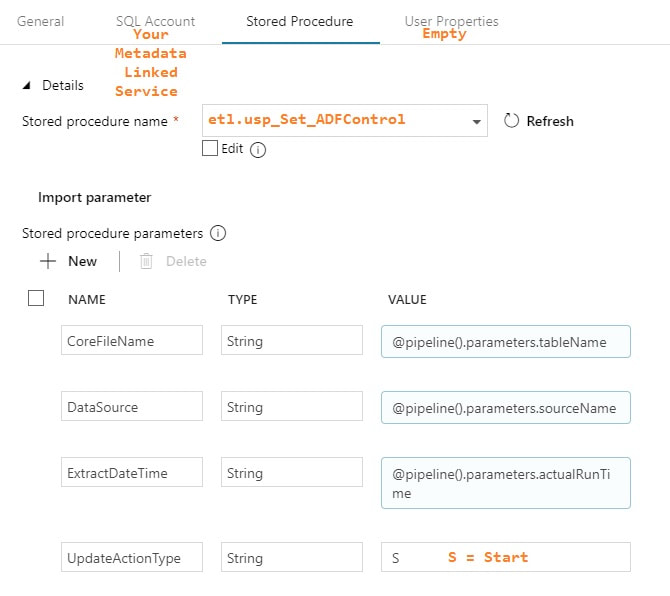
Step #7: Add a second web activity to the pipeline named "Get ADF Execution Metadata" Syntax for this activity is provided in the Microsoft Doc here, but because the documentation leaves so much to the imagination (isn't that a nice way of saying it?), follow the screen prints and copy the syntax provided below. 1 - @concat('https://management.azure.com/subscriptions/', activity('Get Environment Properties').output.firstRow.SubscriptionID, '/resourceGroups/', activity('Get Environment Properties').output.firstRow.ResourceGroupName, '/providers/Microsoft.DataFactory/factories/', activity('Get Environment Properties').output.firstRow.ADFName, '/queryPipelineRuns?api-version=2018-06-01') 3 - application/json 4 - @concat('Bearer ',variables('AccessToken')) 5 - { "lastUpdatedAfter":"@{variables('PriorDateTime')}", "lastUpdatedBefore":"@{variables('CurrentDateTime')}", "filters":[ {"operand":"PipelineName", "operator":"Equals", "values":[ "@{pipeline().parameters.PipelineName}" ] }, {"operand":"Status", "operator":"Equals", "values":[ "InProgress" ] } ] }
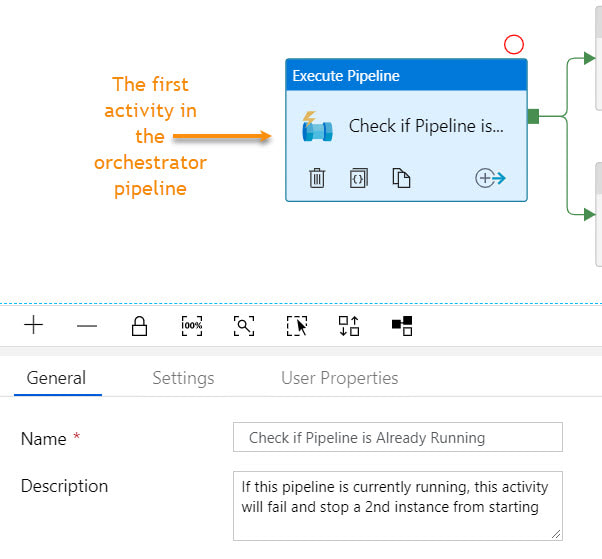
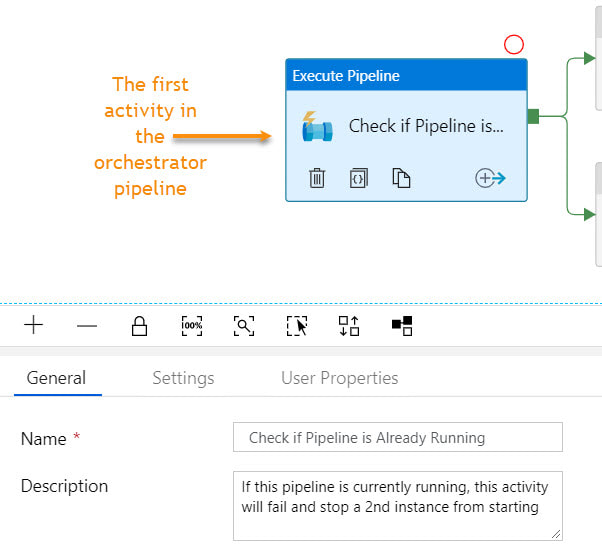
Step #10: Connect the pipeline activities all with green Success arrows. I am including a screen shot of the completed pipeline so that you have a visual of how everything comes together. 
Conclusion of the Matter: I admire people who can wax eloquent about Azure theory and great ideas. Being a Microsoft tool stack mentor and consultant, I simply do not feel prepared unless I can say "I have a POC for that!" I think of this as a "show me the money!" training technique. This is exactly why I have just written a entire chapter in two blog posts. Friend, "this is the money". Go forth and query your ADF pipeline run metadata with confidence!
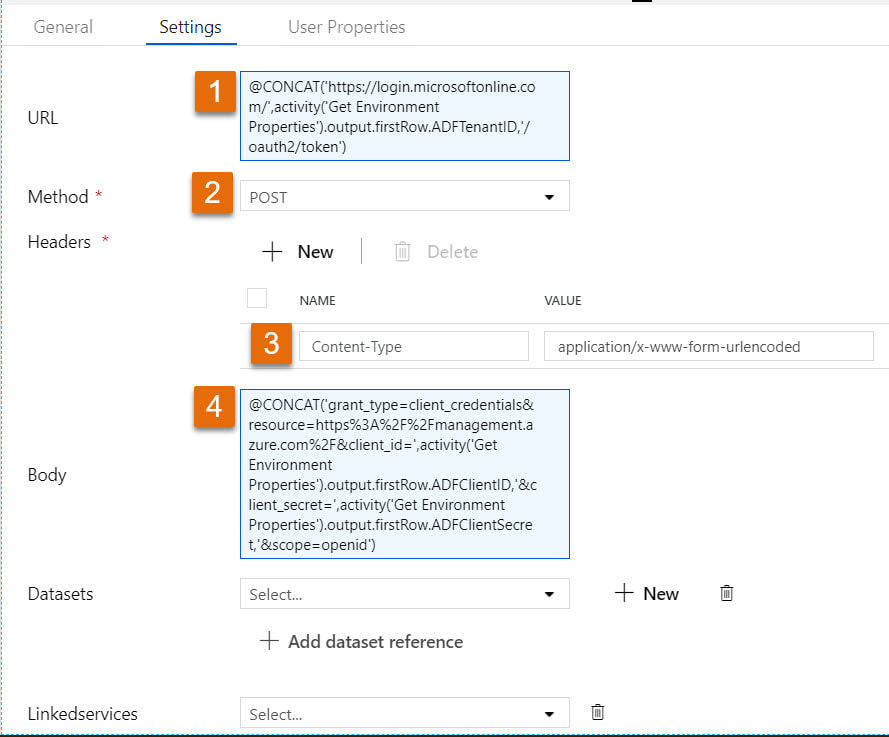
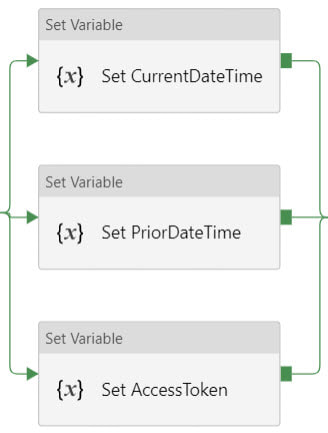
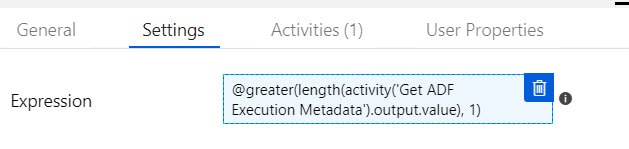
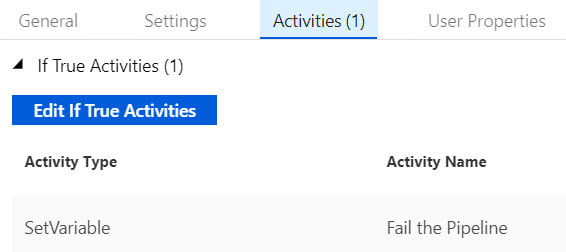
I had a little bit of fun in ADFv2 today and wanted to share my solution for making sure that orchestrator (master) pipelines do not execute concurrently. This can happen for several reasons, but as of August 2019, there is a bug in ADF that causes a single trigger to start a pipeline twice. If you have data-driven incremental loads, this is grossly inconvenient as the metadata tables become completely discombobulated (my technical word of the day). This solution is built on ADFs ability to query pipeline run metadata from the ADF log through a web activity explained here. Come walk with me and let's step through this together. Quick Start Guide If you are familiar with ADF and just want the ten cent tour, follow these steps. Detailed screen prints for each of these steps have been published in blog post 2 of 2 for visual reference. 1. Create a service principal and record the client Id, client secret, tenant Id for future use. 2. Create a file or SQL Server table to hold your environment properties. Add the all three IDs to your environment object. Use Azure Key Vault for your client secret if it is available to you. Assumption: your environment object already contains SubscriptionName, SubscriptionID, ResourceGroupName, and ADFName information. 3. Create a new pipeline with parameters PipelineName as string and MetadataDB as string. Add four variables to the same pipeline named: CurrentDateTime as string, PriorDateTime as string, AccessToken as string and FailThePipeline as boolean. 4. Add a Lookup activity to the pipeline named "Get Environment Properties" and do just that. 5. Add a Web activity to the pipeline named "Get Token" and enter these property values: URL = @concat('https://login.microsoftonline.com/',activity('Get Environment Properties').output.firstRow.ADFTenantID,'/oauth2/token') Method = POST Headers = Content-Type with value = application/x-www-form-urlencoded Body = @concat'grant_type=client_credentials&resource=https%3A%2F%2Fmanagement.azure.com%2F&client_id=',activity('Get Environment Properties').output.firstRow.ADFClientID,'&client_secret=',activity('Get Environment Properties').output.firstRow.ADFClientSecret,'&scope=openid') 6. Add three Set Variable activities to the pipeline and do just that CurrentDateTime variable value = @adddays(utcnow(), +1) PriorDateTime variable value = @adddays(utcnow(), -1) AccessToken variable value = @activity('Get Token').output.access_token 7. Add a second web activity to the pipeline named "Get ADF Execution Metadata URL = @concat('https://management.azure.com/subscriptions/', activity('Get Environment Properties').output.firstRow.SubscriptionID, '/resourceGroups/', activity('Get Environment Properties').output.firstRow.ResourceGroupName, '/providers/Microsoft.DataFactory/factories/', activity('Get Environment Properties').output.firstRow.ADFName, '/queryPipelineRuns?api-version=2018-06-01') Method = POST Headers = Content-Type with value = application/json Authorization with dynamic content value of @concat('Bearer ',variables('AccessToken')) Body = dynamic content value = { "lastUpdatedAfter":"@{variables('PriorDateTime')}", "lastUpdatedBefore":"@{variables('CurrentDateTime')}", "filters":[ {"operand":"PipelineName", "operator":"Equals", "values":[ "@{pipeline().parameters.PipelineName}" ] }, {"operand":"Status", "operator":"Equals", "values":[ "InProgress" ] } ] } 8. Add an If Condition activity to the pipeline named "If Pipeline is Already Running" containing expression dynamic content of @greater(length(activity('Get ADF Execution Metadata').output.value), 1) 9. Add a Set Variable activity to the "If Pipeline is Already Running / If True Activities" activity and name it "Fail the Pipeline" with hard-coded value = Pass string instead of boolean value in order to fail the pipeline. (ADF really needs an "Exit Pipeline" reporting success or failure activity, but let's leave that for another discussion.) 10. Connect the pipeline activities all with green Success arrows. Your pipeline should look like this --> 
Conclusion: I have also published blog post 2 of 2 which contains more detailed screen prints, but just because I have a strong desire to help to make you successful (yes, even though we have not met), I have uploaded the JSON code for this pipeline below. Download it and make it your own.
Sometimes I get so involved in my repeatable processes and project management that I forget to look up. Such is the case of the December 2018 ability to parameterize linked services. I could not rollback and rework all the ADF components this impacted which had already gone to production, but oh hooray! Moving forward, we can now have one linked service per type, one dataset per linked service and one pipeline per ingestion pattern. How sweet is that? Au revoir to the days of one SSIS package per table destination. This is blog post 3 of 3 on using parameters in Azure Data Factory (ADF). Blog post #1 was about parameterizing dates and incremental loads. Blog post #2 was about table names and using a single pipeline to stage all tables in a source. Today I am talking about parameterizing linked services. Disclaimer: Not all linked service types can be parameterized at this time. This feature only applies to eight data stores:
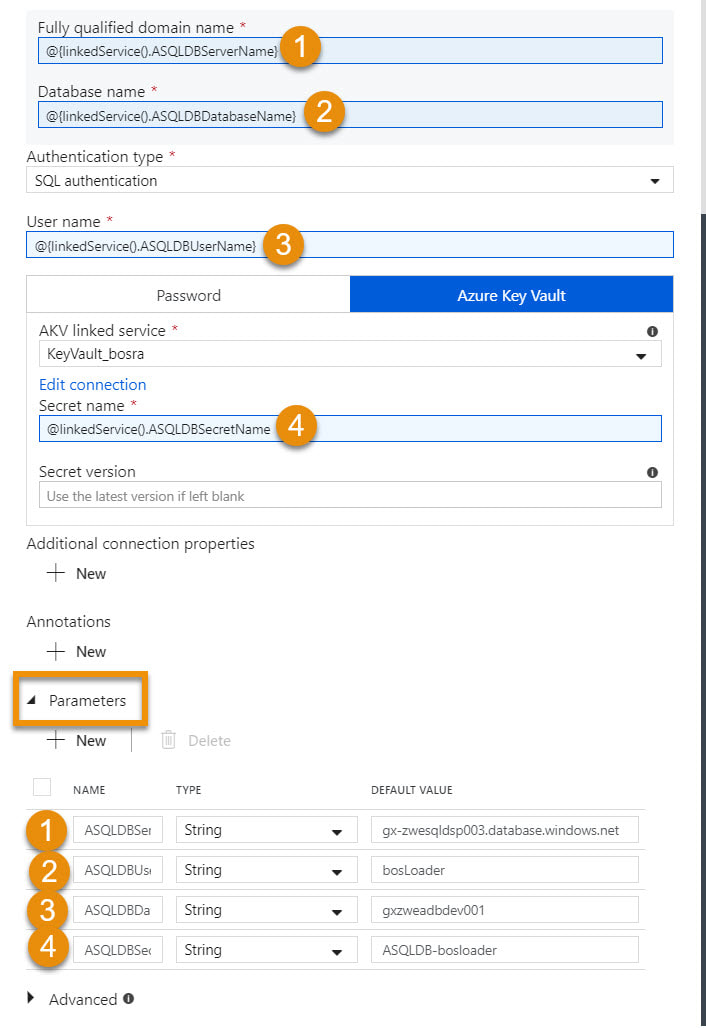
Concept Explained: The concept is pretty straightforward and if our goal is to have one linked service per type, a parameterized Azure SQL Database linked service might look like this:
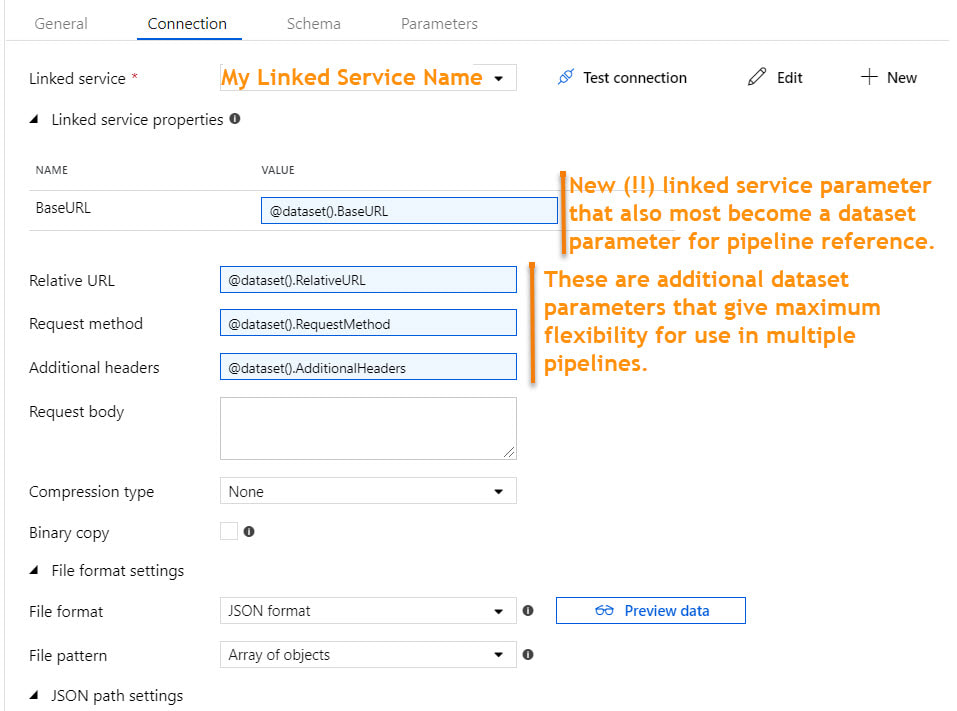
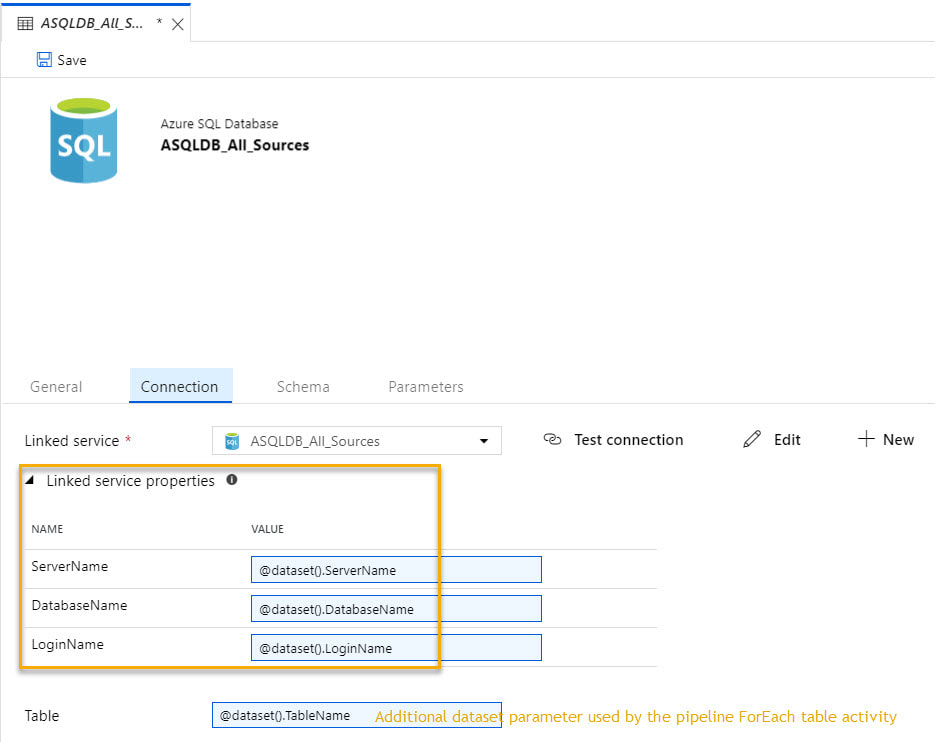
Moving on the the single dataset that uses this linked service, we have the following.
Putting it all Together: 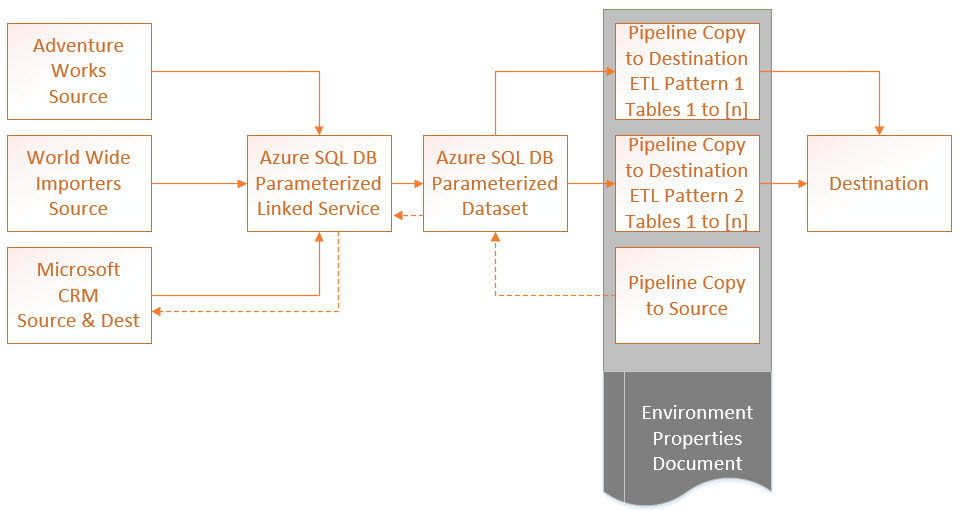 What we are after here is a repeatable process, simplicity of design, fewer developer hours, easier deployments and more efficient DevOps. We also want very little hard-coding of parameter values; thus the environment properties document. If we find that we have lost flexibility in our pipelines that are "doing to much" and a change impacts "too many destinations", rethink the parameters and kick them up a notch. Even with the above design, we should be able to execute the load of just one source, or just one table of a source. We should also be able to complete data-driven full and incremental loads with these same pipeline activities. Metadata ADF control tables and ADF orchestrator pipelines (pipelines that call other child pipelines and govern dependency), can also be helpful.
Final Musings: Obviously the above pattern works best if you are staging your data into your destination, then doing your transform and load (ELT). This brings me to a growing realization that with SSIS I had turned away from transform user stored procedures (USPs) and became disciplined in using SSIS in-memory capabilities. With a recent Azure Data Warehouse project, however, I had to renew my love of USPs. So now I am, quite frankly, betwixt and between ADF parameter capabilities for staging, Databricks performance capabilities for transforms, and our old friend, the stored procedure. For everything there is an appropriate place, so once again, let's get back to the architecture diagram and figure out what works best for your unique requirements. This is my second attempt to articulate lessons learned from a recent global Azure implementation for data and analytics. My first blog post became project management centered. You can find project management tips here. While writing it, it became apparent to me that the tool stack isn't the most important thing. I'm pretty hard-core Microsoft, but in the end, success was determined by how well we coached and trained the team -- not what field we played on. Turning my attention in this blog post to technical success points, please allow me to start off by saying that with over twenty countries dropping data into a shared Azure Data Lake, my use of "global" (above) is no exaggeration. I am truly not making this all up by compiling theories from Microsoft Docs. Second, the most frequent question people ask me is "what tools did you use?", because migrating from on-prem, Microsoft SSIS or Informatica to the cloud can feel like jumping off the high dive at the community pool for the first time. Consequently, I'm going to provide the tool stack list right out of the gate. You can find a supporting diagram for this data architecture here. Microsoft Azure Tool Stack for Data & Analytics Hold on, your eyes have already skipped to the list, but before you make an "every man for himself" move and bolt out of the Microsoft community pool, please read my migration blog post. There are options! For example, I just stood up an Azure for Data & Analytics solution that has no logic apps, Azure function, event hub, blob storage, databricks, HDI, or data lake. The solution is not event-driven and takes an ELT (extract, load, and then transform) approach. It reads from sources via Azure Data Factory and writes to an Azure Database logging the ELT activities in an Azure Database as well. Now, how simple is that? Kindly, you don't have to build the Taj MaSolution to be successful. You do have to fully understand your customer's reporting and analysis requirements, and who will be maintaining the solution on a long-term basis. If you still wish to swan dive into the pool, here's the list! 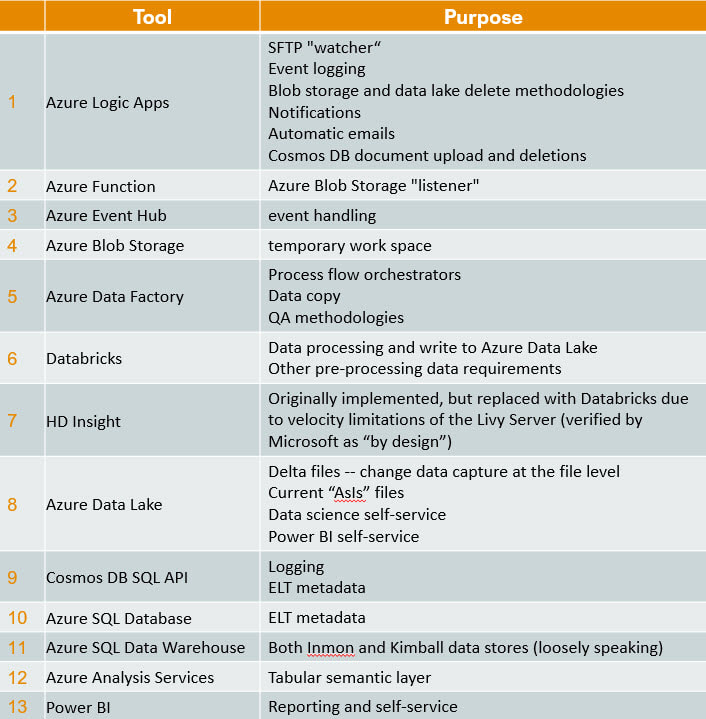 Disclaimer: This blog post will not address Analysis Services or Power BI as these are about data delivery and my focus today is data ingestion. Technical Critical Success Points (CSP) Every single line item above has CSPs. How long do you want to hang out with me reading? I'm with you! Consequently, here are my top three CSP areas. Azure Data Factory (ADF)
Azure Data Lake (ADL)
Data Driven Ingestion Methodology
Wrapping It Up Supporting Applications It is only honest to share three supporting applications that help to make all of this possible.  Link to creating a Python project in Visual Studio. Link to Azure SQL Data Warehouse Data Tools (Schema Compare) preview information. At the writing of this post, it still has to be requested from Microsoft and direct feedback to Microsoft is expected. Link to integrate Azure Data Factory with GitHub. Link to integrate Databricks with GitHub. Sample Files Below are example of data driven metadata and environment properties. Both are in JSON format.
A Bit of Humor Before You Go Just for fun, here are some of my favorite sayings in no certain order
I have been on a long term Azure for BI implementation and took some time today for a "what went right", "what went wrong" and "what I'll do differently" introspection. Giving the outcome a bit of a positive twist, I'll try not to repeat what I've already shared in Data Architecture for BI Programs and Transitioning from Traditional to Azure Data Architectures. I actually thought I'd write about parameterized shared ADF datasets, or using Python to auto generate transform views and load store procedures. Instead, it appears that my fingers have reverted back to tool agnostic critical success points. (You can find my technical tips / introspection here.) My tool agnostic thoughts: Go Get Your First Customer! Here is a movie quote for you: "Build it and they will come". This thought process should be sent straight to Hades. Data architecture and analytics is not a Field of Dreams. Among other things, having an actual customer will result in a finished product that at least somebody wants. The best advertisement is word of mouth, and it is easier to sell a product that has at least one happy customer. It amazes me to see how many companies make this mistake. If you do not have one already, go get your first customer and put them on your design team. Now, how easy was that?! Associate Each Data Architectural Decision with a Business Value In my most recent project, my colleague, Joshuha Owen, and I put together a slide deck affiliating business value with data architectural decisions. There were several slides that looked similar to this for business users-->  When trying to explain event-driven data ingestion to the technical team, I turned it around to look something like this --> 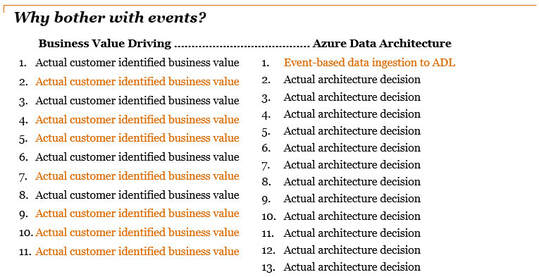 The point is: bring business value or bust. You can have all the data in the world sitting in your data lake or warehouse, but if your non-technical users can't do something with it, there is no business value. With no business value, your budget gets cut. Deliver Incremental Business Value Here is a popular thought: "Agile project management". When I worked for <some company that shall not be named who is NOT a recent engagement> they professed to be agile, but spelled it with a lower case "a". This meant that they had created their own manifesto. My recollection is a whole lot of waterfall in a lower case "a" implementation. I have observed that a team can have scrums, sprint planning, epics, features, user story points and tasks but if there are bringing several subject areas coming across the finish line at the same time, I feel that the ROI for delivering incremental business value earlier in the timeline has been lost. Here is a very simple example. This is not agile, Agile, or anyone's good idea -->  However, let's be fair. You will end up in a similar situation as pictured above when you have extenuating circumstances, like waiting for approvals, or your application vendor pushes an update to the Cloud which causes you to rework previously completed work. Projects have roadblocks that skew our perfectly planned timelines. What I am trying to communicate is that the above picture should not be your planned strategy for business value delivery. In contrast, this is a very simplified picture of agile, Agile, or someone's great idea -->  Hold Something Back. This is my new project management strategy learned from my recent engagement. I'm not a licensed PM, but I have come to love this idea. How many times have we wanted to "exceed expectations" so we deliver more than what was promised? Problem is, we are back in stress mode for the next delivery date. How about exceeding expectations, but delivering that extra bit mid-timeline? In other words, think about "keeping something completed in your back pocket". This is hard for me...I want to hit the ball out of the park every time, but how boring is that? Imagine if every batter hit the ball out of the park -- hot dogs and peanuts would be the best part of the game. You know what's fun? BASES LOADED! So ... let's load the timeline.  I have found myself in the above scenario when subject areas overlap in planning effort and therefore require less design or development because we have established a repeatable process.
If you have worked with me 1:1, how many times have I said, "we can, but we won't"? Wait 1, 2 & 3 are examples of holding something back -- you could go to production, but you don't /or/ you are in production but no one knows. (I prefer the latter.) Summary of the Matter Once again, my patient reader, thanks for reading! I value your time, and I feel honored if you are actually reading this last sentence. I love Azure for BI because it can be really fun (!!). Please post your own personal experiences, and let's help each other be successful. Confession: I put a lot of subtexts in this blog post in an attempt to catch how people may be describing their move from SSIS to ADF, from SQL DBs, to SQL DWs or from scheduled to event-based data ingestion. The purpose of this post is to give you a visual picture of how our well loved "traditional" tools of on-prem SQL Databases, SSIS, SSAS and SSRS are being replaced by the Azure tool stack. If you are moving form "Traditional Microsoft" to "Azure Microsoft" and need a road map, this post is for you. Summary of the Matter: If you only read one thing, please read this: transitioning to Azure is absolutely "doable", but do not let anyone sell you "lift and shift". Azure data architecture is a new way of thinking. Decide to think differently. First Determine Added Value: Below are snippets from a slide deck I shared during Pragmatic Work's 2018 Azure Data Week. (You can still sign up for the minimal cost of $29 and watch all 40 recorded sessions, just click here.) However, before we begin, let's have a little chat. Why in the world would anyone take on an Azure migration if their on-prem SQL database(s) and SSIS packages are humming along with optimum efficiency? The first five reasons given below are my personal favorites.
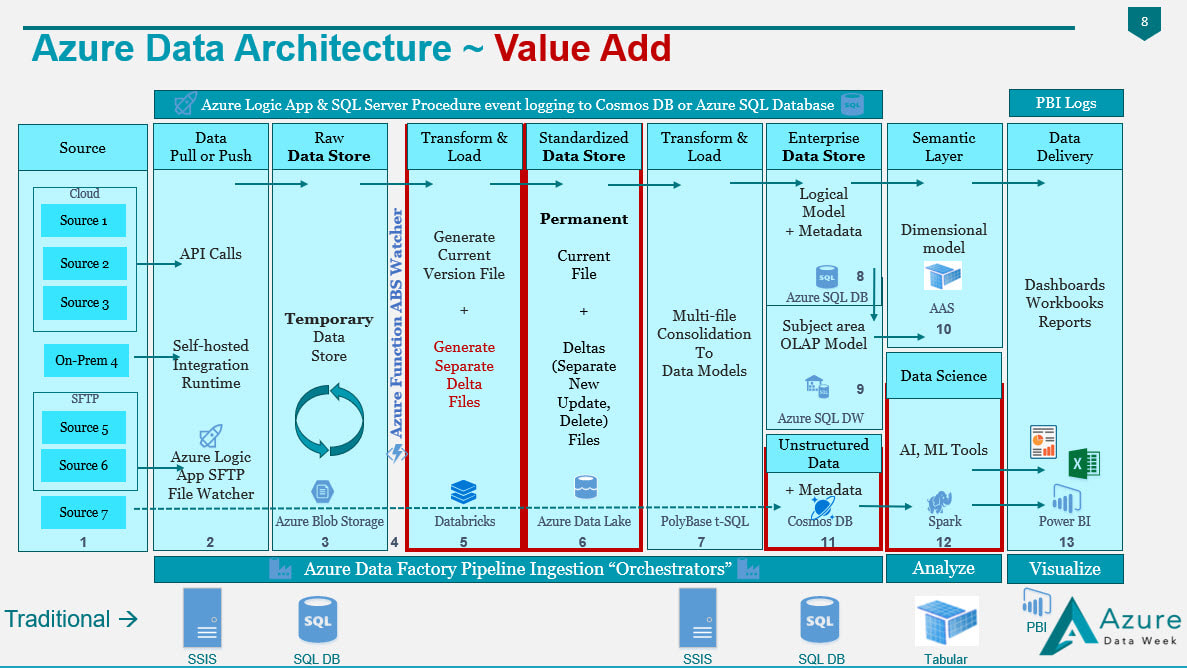 Figure 1 - Value Added by an Azure Data Architecture If you compare my Traditional Data Architecture diagram first posted on this blob site in 2015 and the Azure Data Architecture diagram posted in 2018, I hope that you see what makes the second superior to the first is the value add available from Azure. In both diagrams we are still moving data from "source" to "destination", but what we have with Azure is an infrastructure built for events (i.e. when a row or file is added or modified in a source), near real time data ingestion, unstructured data, and data science. In my thinking, if Azure doesn't give us added value, then why bother. A strict 1:1 "traditional" vs "Azure" data architecture would look something like this (blue boxes only) --> 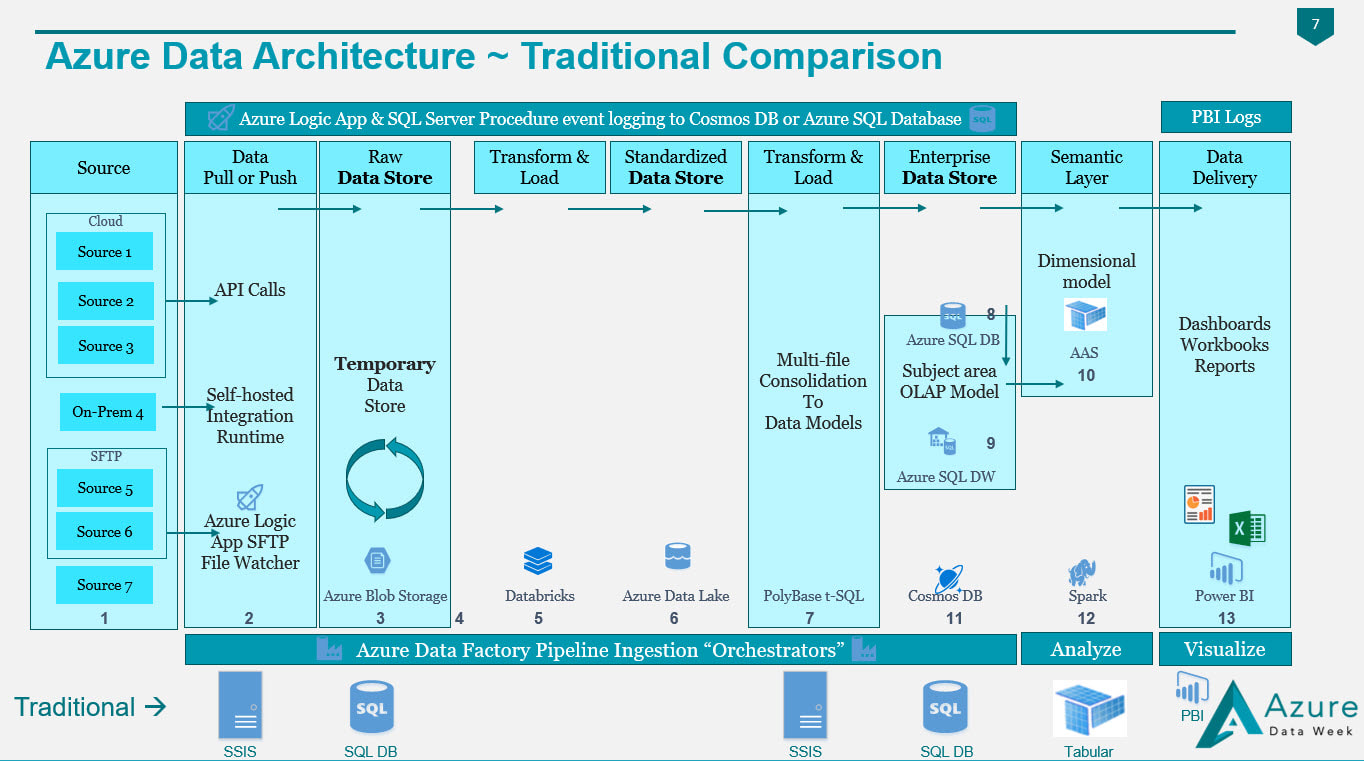 Figure 2 - Traditional Components Aligned with Azure Components It is the "white space" showing in Figure 2 that gives us the added value for an Azure Data Architecture. A diagram that is not from Azure Data Week, but I sometime adapt to explain how to move from "traditional" to "Azure" data architectures is Figure 3. It really is the exact same story as Figure 2, but I've stacked "traditional" and "Azure" in the same diagram. 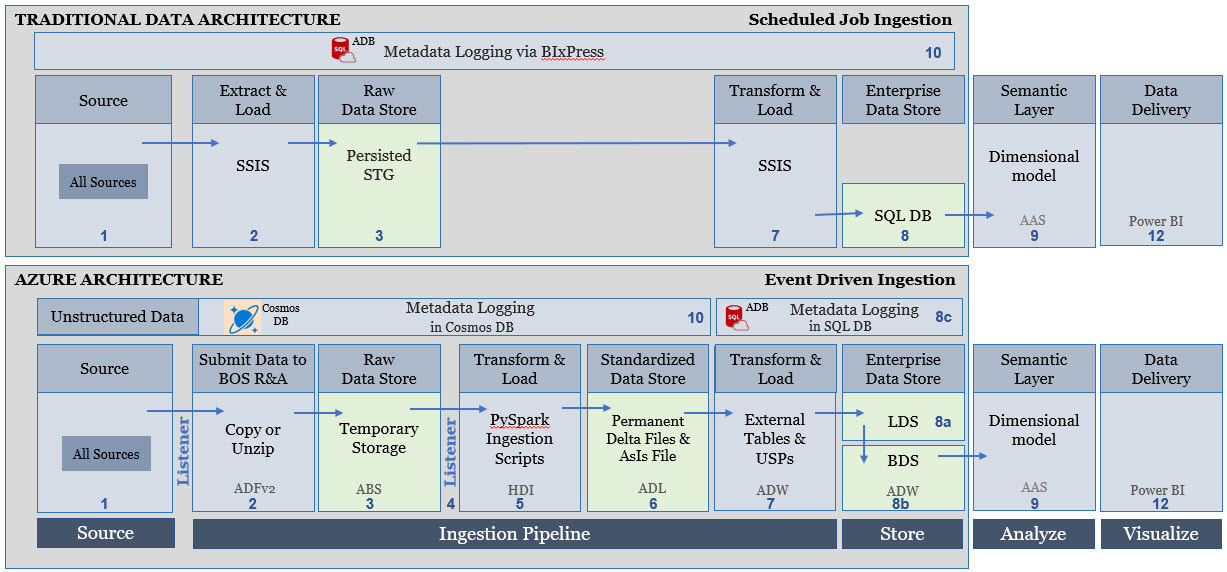 Figure 3 - Traditional Components Aligned with Azure Components (Second Perspective) Tips for Migration: Having worked with SQL Server and data warehouses since 1999 (Microsoft tool stack specifically), I am well aware of the creative solutions to get "near real time" from a SQL Agent job into an on-prem SQL Server, or to query large data sets effectively with column store indexing. For the sake of argument, let's say that nothing is impossible in either architecture. The point I'm trying to make here, however, is rather simple:
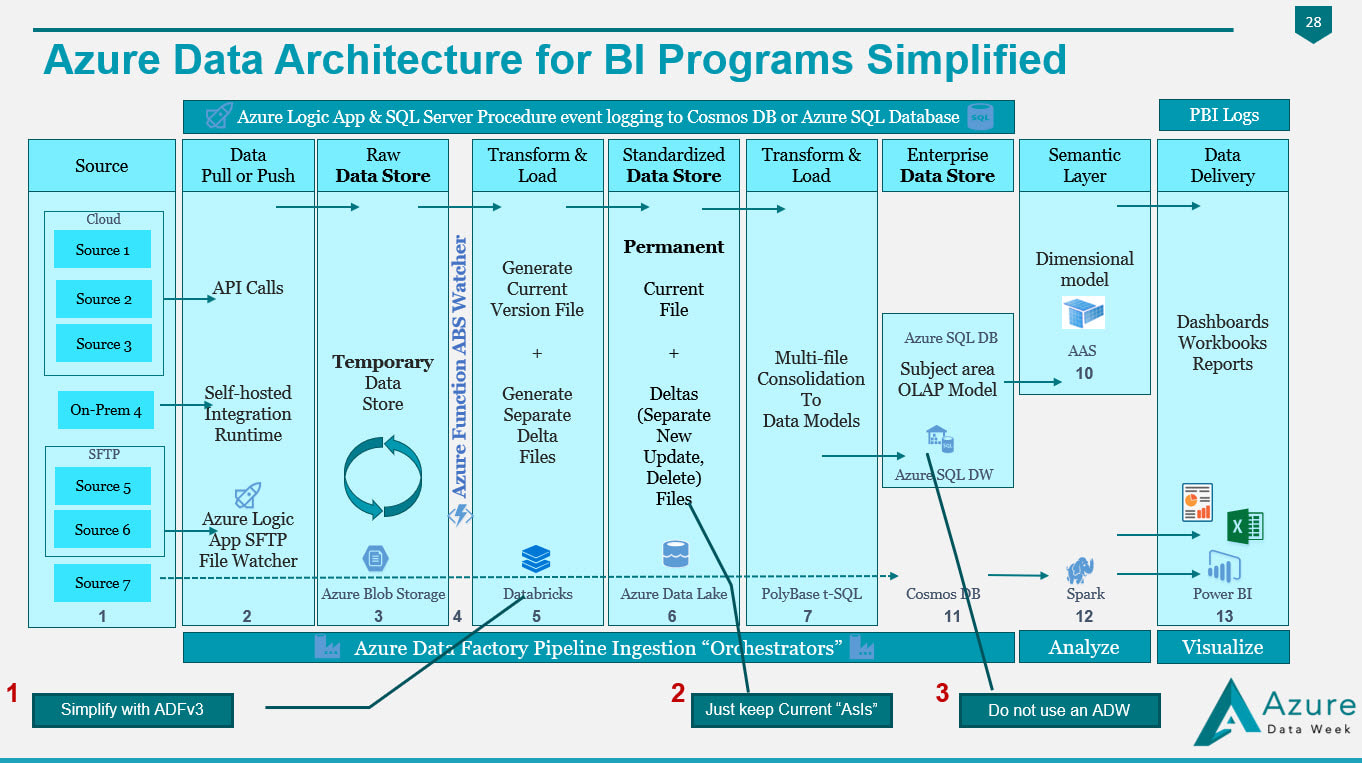 Figure 4 In Figure 4, we have made the following substitutions to simplify migration:
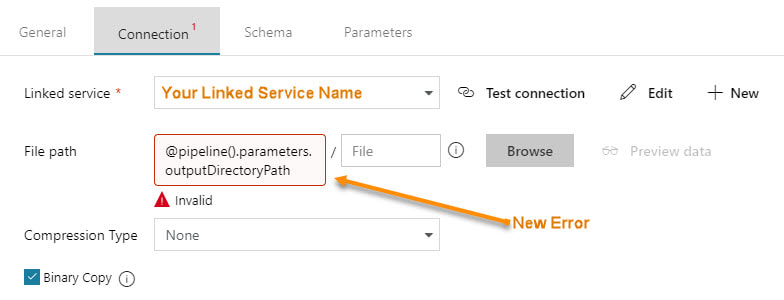
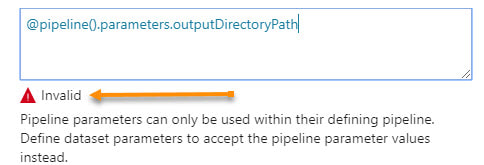
1. We have selected Azure Data Factory version 3 to replace the Python of Databricks or the PySpark of HDInsight. 2. We have removed the change data capture files in Azure Data Lake and are keeping simple "is most recent" files. 3. Unless you have data volumes to justify a data warehouse, which should have a minimum of 1 million rows for each of its 60 partitions, go with an Azure Database! You'll avoid the many creative solutions that Azure Data Warehouse requires to offset its unsupported table features, and stored procedures limitations Every company I work with has a different motivation for moving to Azure, and I'm surely not trying to put you into my box. The diagrams shared on my blob site change with every engagement, as no two companies have the same needs and business goals. Please allow me to encourage you to start thinking as to what your Azure Data Architecture might look like, and what your true value add talking points for a migration to Azure might be. Moving onward and upward, my technical friend, ~Delora Bradish p.s. If you have arrived at the blog post looking for a Database vs Data Warehouse, or Multidimensional vs Tabular discussion, those really are not Azure discussion points as much as they are data volume discussion points; consequently, I did not blog about these talking points here. Please contact me via www.pragmaticworks.com to schedule on site working sessions in either area. Summary of the Matter: Parameter passing in ADFv2 had a slight change in the summer of 2018. Microsoft modified how parameters are passed between pipelines and datasets. Prior, you could reference a pipeline parameter in a dataset without needing to create a matching dataset parameter. The screen prints below explain this much better, and if you are new to ADFv2 and parameter passing, this will give you a nice introduction. I personally feel the change is an improvement. New Warnings and Errors My client had been using ADFv2 since the beginning of 2018, then on a particular Monday, we walked into the office and noticed that our ADFv2 datasets were throwing errors and warnings.
Thankfully, Microsoft made this change backward compatible to an extent, so our pipelines were still humming merrily along. The new methodology is actually an improvement, so let's go with it! Here are the summary steps to correct the problem:
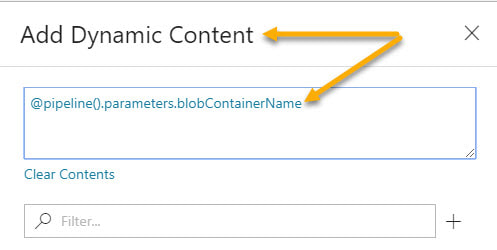
Step #1 - In the dataset, create parameter(s). 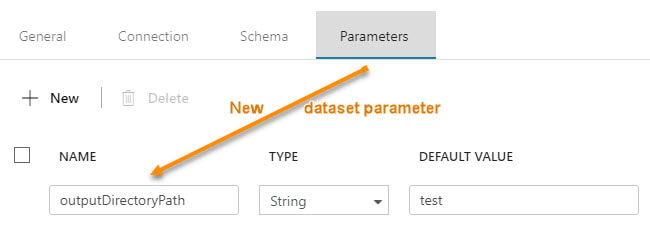 Step #2 - In the dataset, change the dynamic content to reference the new dataset parameters 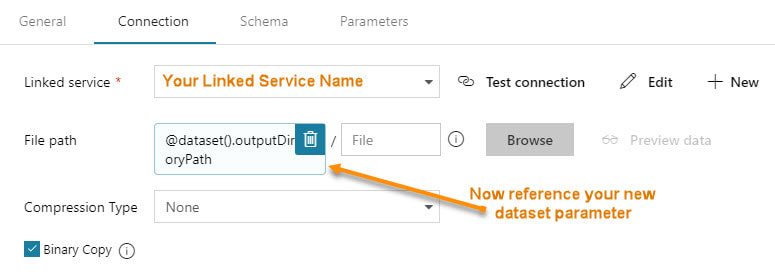 The content showing above used to read "@pipeline().parameters.outputDirectoryPath". You now have to reference the newly created dataset parameter, "@dataset().outputDirectoryPath". Step #3 - In the calling pipeline, you will now see your new dataset parameters. Enter dynamic content referencing the original pipeline parameter. 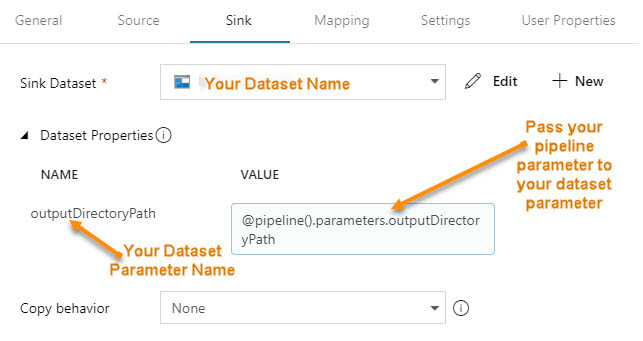 Conclusion:
The advantage is now we can explicitly pass different values to the dataset. As a dataset is an independent object and is called by a pipeline activity, referencing any sort of pipeline parameter in the dataset causes the dataset to be "orphaned". What if you want to use that dataset in a pipeline that does not have our example parameter "outputDirectoryPath"? Prior, your pipeline would fail, now you can give the dataset parameter a default inside the dataset. Better yet, your two parameter names do not have to match. In step #3, the pipeline screen print immediately above, you can put any parameter reference, system variable or function in the "VALUE". That's pretty much all there is to it! If you haven't already, start editing. When testing Azure Data Lake (ADL) to Azure Data Warehouse (ADW) file ingestion, this error continued to come up on various external table SELECTs. The confusion was that the ADL only contained parquet files. There was only one external file format defined, and that too was obviously for parquet. From where was an RCFile error originating? The bottom line, in this particular engagement scenario, was that this error is actually a truncation error.
Things to Verify:
Solution:
Supporting t-sql Scripts If you are new to PolyBase and external tables in SQL Server environments, here are a three t-sql scripts that are supporting references to the error resolution given above. Example CREATE EXTERNAL DATA SOURCE t-SQL. Click here for more information. CREATE EXTERNAL DATA SOURCE [MyDataSourceName] WITH (TYPE = HADOOP, LOCATION = N'adl://MyDataLakeName.azuredatalakestore.net', CREDENTIAL = [MyCredential]) GO Example CREATE EXTERNAL FILE FORMAT t-SQL. Click here for more information. CREATE EXTERNAL FILE FORMAT [MyFileFormatName] WITH (FORMAT_TYPE = PARQUET , DATA_COMPRESSION = N'org.apache.hadoop.io.compress.SnappyCodec') GO Example CREATE EXTERNAL TABLE t-sql script. Click here for more information. BEGIN TRY DROP EXTERNAL TABLE [ext].[MyExternalTableName] END TRY BEGIN CATCH END CATCH CREATE EXTERNAL TABLE [ext].[MyExternalTableName] ( [ColumnName1] bigint NULL ,[ColumnName2] nvarchar(4000) NULL -- if this value is too small, you will get the conversion error ,[ColumnName3] bit NULL ,[ColumnName4] datetime NULL ,[ADLcheckSum] nvarchar(64) NULL -- if this value is too small, you will get the conversion error ,[ADFIngestionId] nvarchar(64) NULL -- if this value is too small, you will get the conversion error ) WITH (DATA_SOURCE = [MyDataSourceName] , LOCATION = N'/Folder1/Folder2/' , FILE_FORMAT = [MyFileFormatName] , REJECT_TYPE = VALUE ,REJECT_VALUE = 0) GO In the first of three blog posts on ADFv2 parameter passing, Azure Data Factory (ADFv2) Parameter Passing: Date Filtering (blog post 1 of 3), we pretty much set the ground work. Now that I hope y'll understand how ADFv2 works, let's get rid of some of the hard-coding and make two datasets and one pipeline work for all tables from a single source. You know I have to say it ... can SSIS "show me [this] money"? This solution consists of three ADFv2 objects (yes, only three!!)
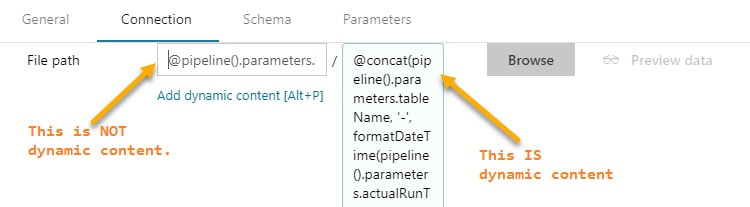
Assumption: You have read blog post 1 of 3 on parameter passing with ADFv2 and now understand the basic concept of parameter passing and concatenating values in ADFv2. Summary: This blog post builds on the first blog and will give you additional examples of how to pass a table name as dynamic content. It will show you how to use a 1.) single input dataset, 2.) single output dataset and 3.) single pipeline to extract data from all tables in a source. Setup: The JSON for all datasets and pipelines is attached below, but if you take a moment to understand the screen prints, it might be easier than reading JSON. 1. Single Input Dataset 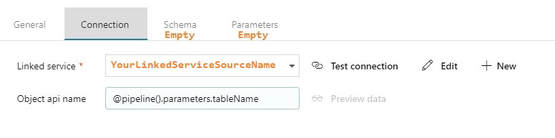 2. Single Output Dataset File path prefix --> @pipeline().parameters.blobContainerName File path suffix --> @concat(pipeline().parameters.tableName, '-', formatDateTime(pipeline().parameters.actualRunTime, 'yyyy'), formatDateTime(pipeline().parameters.actualRunTime,'MM'), formatDateTime(pipeline().parameters.actualRunTime,'dd'),' ' , formatDateTime(pipeline().parameters.actualRunTime,'hh'), formatDateTime(pipeline().parameters.actualRunTime, 'mm'), '.txt') 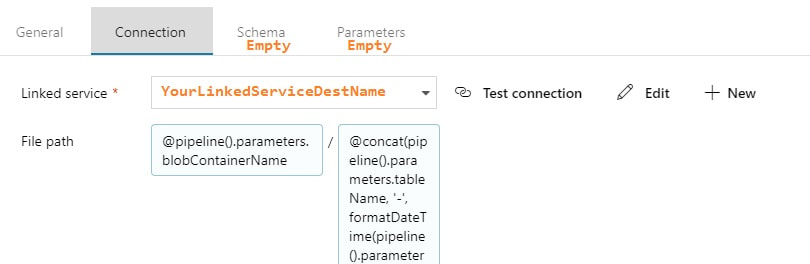 Tip: Dynamic content and text values that contain an "@pipline..." syntax are not the same thing.
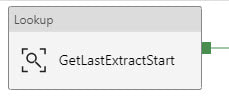
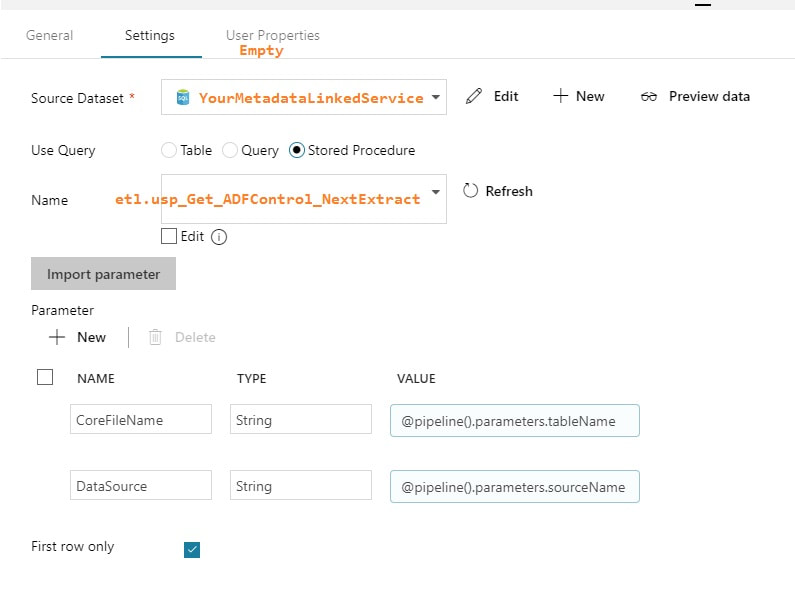
3. Single ADFv2 Pipeline The primary add-in for this blog post is the lookup for a column list and the additional parameter being used for the table name. The @pipeline().parameters.actualRunTime value is passed by an Azure Logic App not explained here, or you could use the pipeline start or a utcdate. In blog post 3 of 3 we are going to put in a ForEach loop that will allow us to spin through a list of tables.  Lookup Activity - GetLastExtractStart
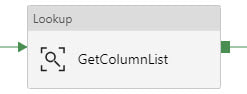
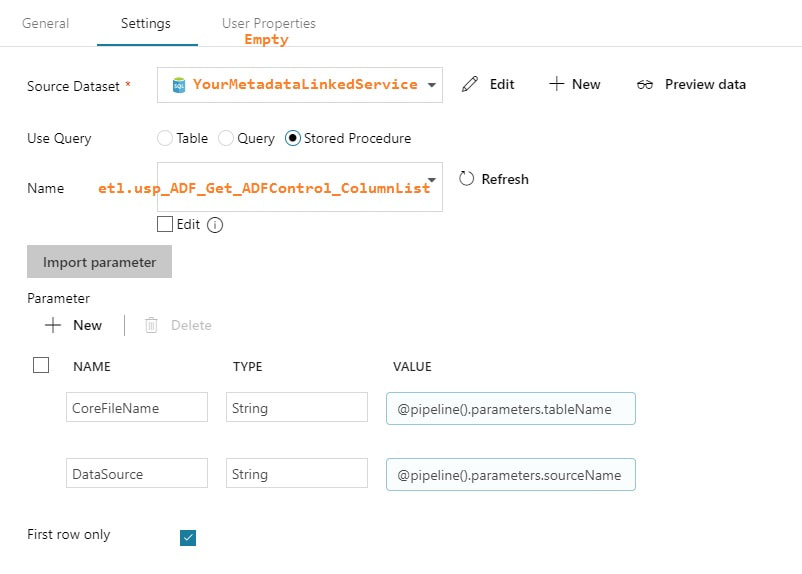
Lookup Activity -GetcolumnList
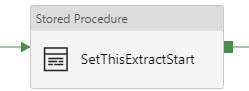
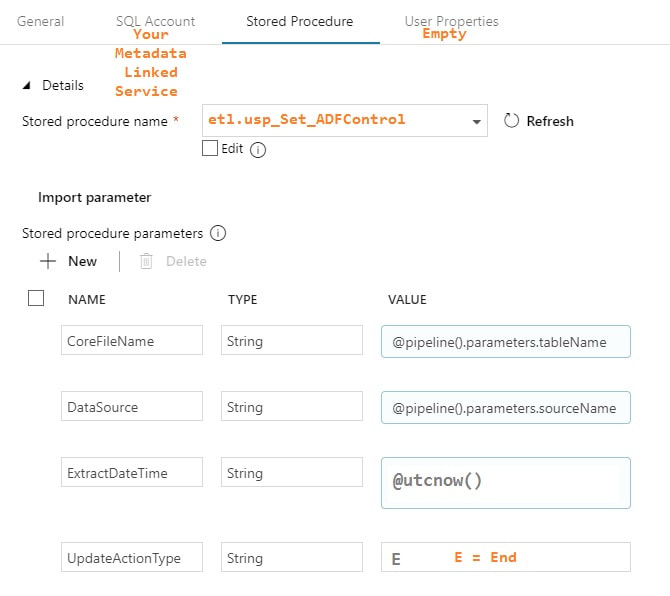
Execute Stored Procedure - SetThisExtractStart
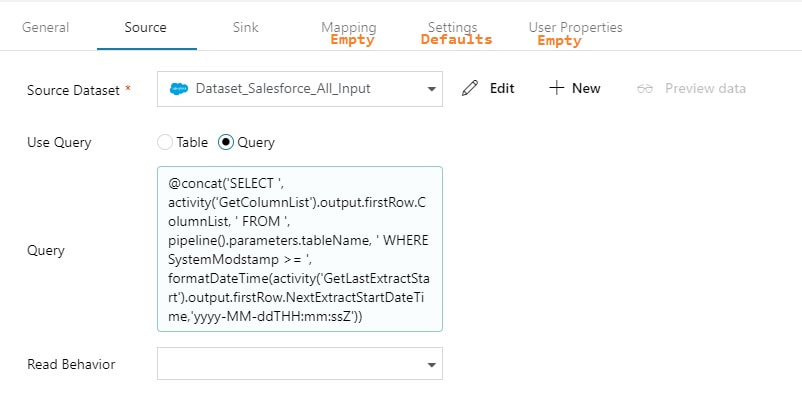
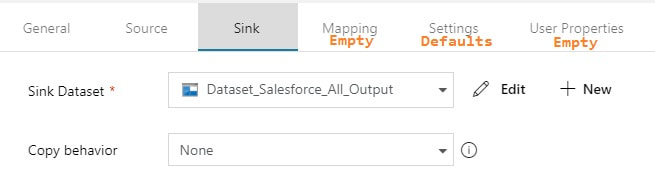
Copy Activity This is where it all comes together. You concatenate your looked up column list with your looked up table name, and now you are using a single input dataset for all source tables. 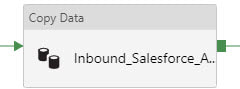 @concat('SELECT ', activity('GetColumnList').output.firstRow.ColumnList, ' FROM ', pipeline().parameters.tableName, ' WHERE SystemModstamp >= ', formatDateTime(activity('GetLastExtractStart').output.firstRow.NextExtractStartDateTime,'yyyy-MM-ddTHH:mm:ssZ'))
Execute Stored Procedure - SetThisExtractEnd
The Conclusion of the Matter: I've taken the time to provide all of these screen prints in loving memory of SSIS. Once you transition, you can figure most of this out with a bit of persistence, but isn't it nice to have screen prints to show you the way sometimes? The most challenging part of this is the @concat() of the source copy activity. Every data source will require this in their own syntax (SOSQL, t-sql etc.), or beware -- in the syntax of the ODBC driver that is sitting behind Microsoft's data connector. Link to Azure Data Factory (ADF) v2 Parameter Passing: Date Filtering (blog post 1 of 3) Link to Azure Data Factory (ADF) v2 Parameters Passing: Linked Services (blog post 3 of 3) Supporting Downloadable Files:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||






 RSS Feed
RSS Feed
