|
Confession: I put a lot of subtexts in this blog post in an attempt to catch how people may be describing their move from SSIS to ADF, from SQL DBs, to SQL DWs or from scheduled to event-based data ingestion. The purpose of this post is to give you a visual picture of how our well loved "traditional" tools of on-prem SQL Databases, SSIS, SSAS and SSRS are being replaced by the Azure tool stack. If you are moving form "Traditional Microsoft" to "Azure Microsoft" and need a road map, this post is for you. Summary of the Matter: If you only read one thing, please read this: transitioning to Azure is absolutely "doable", but do not let anyone sell you "lift and shift". Azure data architecture is a new way of thinking. Decide to think differently. First Determine Added Value: Below are snippets from a slide deck I shared during Pragmatic Work's 2018 Azure Data Week. (You can still sign up for the minimal cost of $29 and watch all 40 recorded sessions, just click here.) However, before we begin, let's have a little chat. Why in the world would anyone take on an Azure migration if their on-prem SQL database(s) and SSIS packages are humming along with optimum efficiency? The first five reasons given below are my personal favorites.
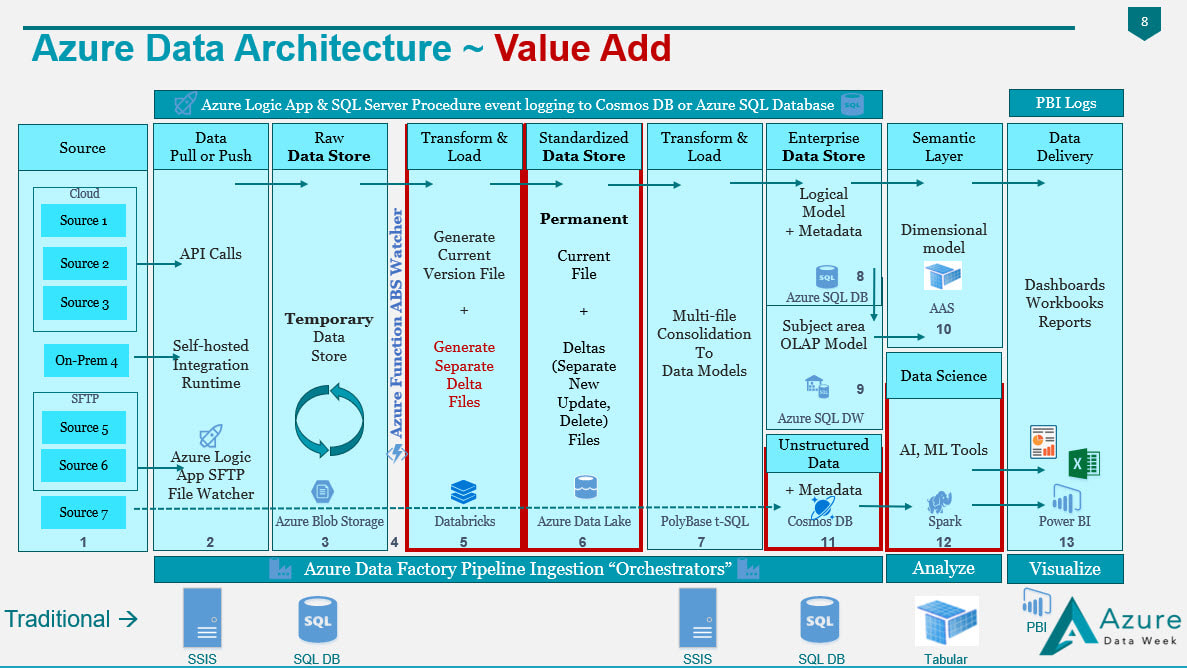 Figure 1 - Value Added by an Azure Data Architecture If you compare my Traditional Data Architecture diagram first posted on this blob site in 2015 and the Azure Data Architecture diagram posted in 2018, I hope that you see what makes the second superior to the first is the value add available from Azure. In both diagrams we are still moving data from "source" to "destination", but what we have with Azure is an infrastructure built for events (i.e. when a row or file is added or modified in a source), near real time data ingestion, unstructured data, and data science. In my thinking, if Azure doesn't give us added value, then why bother. A strict 1:1 "traditional" vs "Azure" data architecture would look something like this (blue boxes only) --> 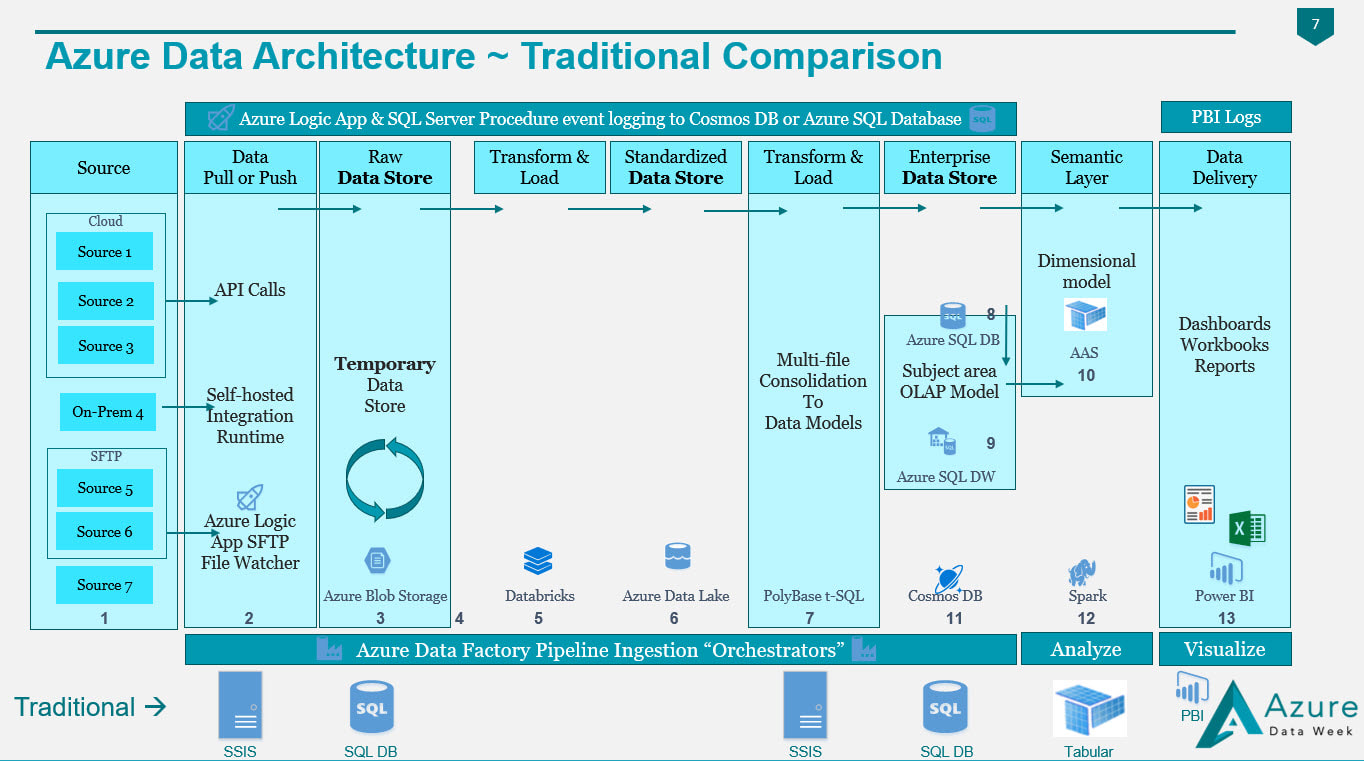 Figure 2 - Traditional Components Aligned with Azure Components It is the "white space" showing in Figure 2 that gives us the added value for an Azure Data Architecture. A diagram that is not from Azure Data Week, but I sometime adapt to explain how to move from "traditional" to "Azure" data architectures is Figure 3. It really is the exact same story as Figure 2, but I've stacked "traditional" and "Azure" in the same diagram. 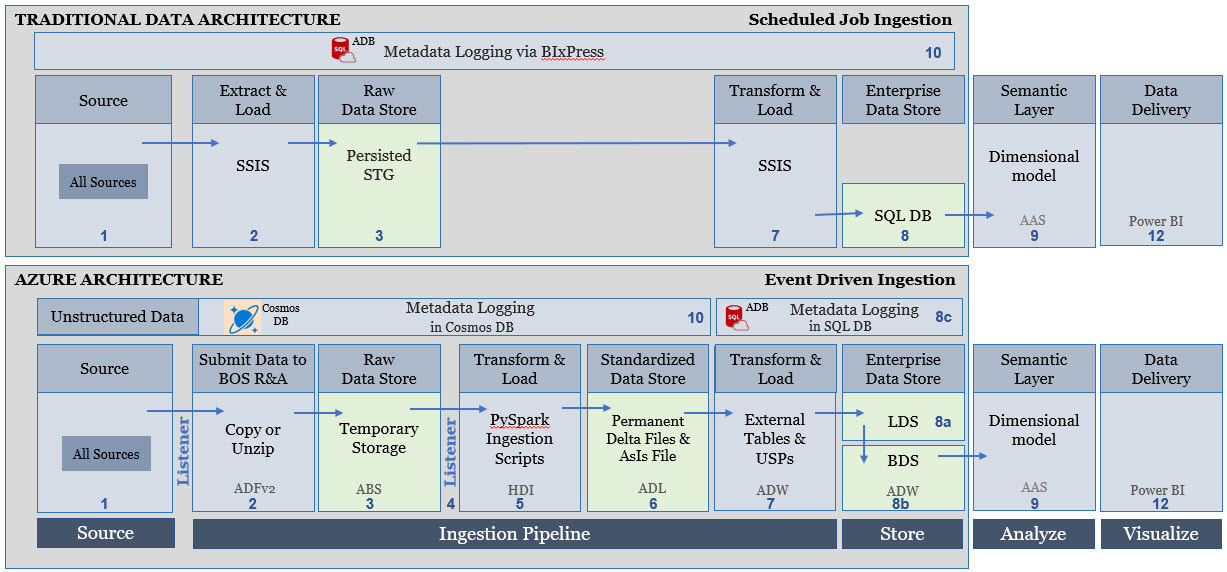 Figure 3 - Traditional Components Aligned with Azure Components (Second Perspective) Tips for Migration: Having worked with SQL Server and data warehouses since 1999 (Microsoft tool stack specifically), I am well aware of the creative solutions to get "near real time" from a SQL Agent job into an on-prem SQL Server, or to query large data sets effectively with column store indexing. For the sake of argument, let's say that nothing is impossible in either architecture. The point I'm trying to make here, however, is rather simple:
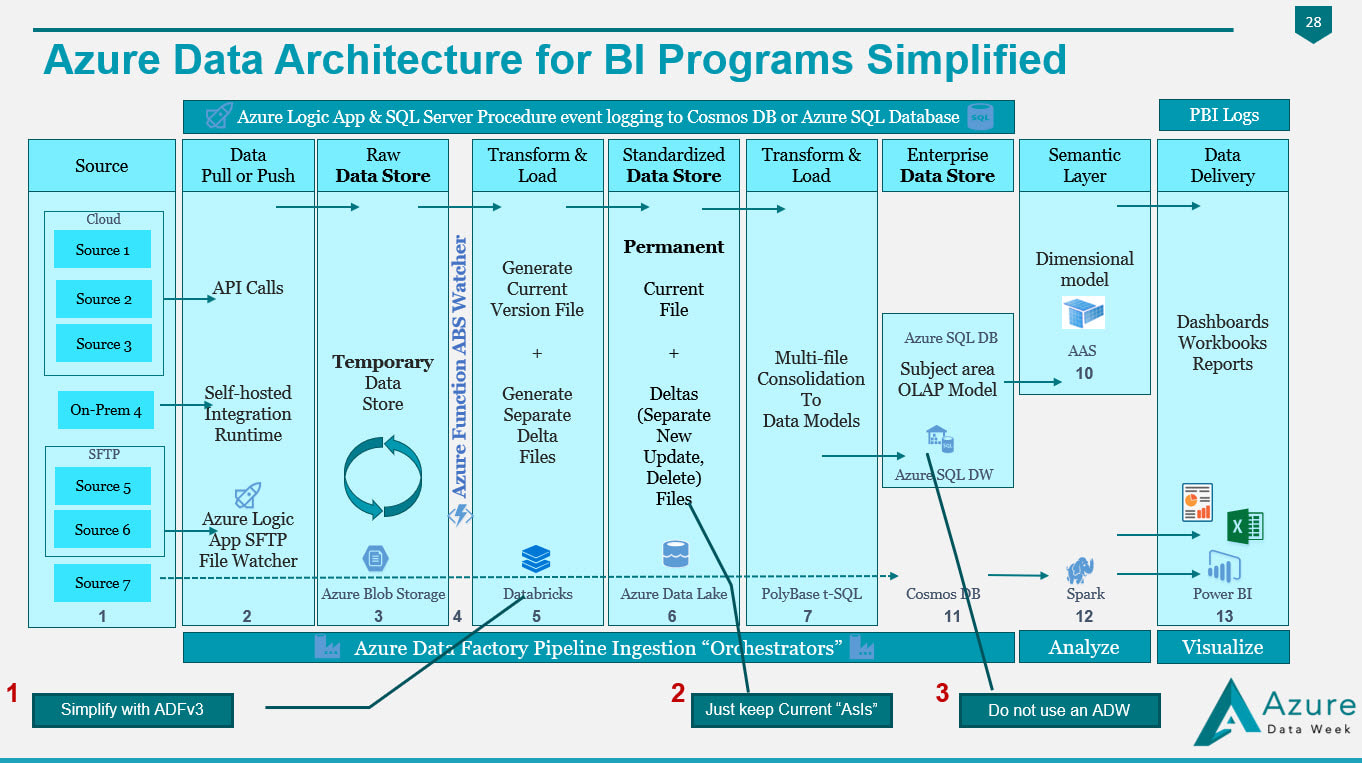 Figure 4 In Figure 4, we have made the following substitutions to simplify migration:
1. We have selected Azure Data Factory version 3 to replace the Python of Databricks or the PySpark of HDInsight. 2. We have removed the change data capture files in Azure Data Lake and are keeping simple "is most recent" files. 3. Unless you have data volumes to justify a data warehouse, which should have a minimum of 1 million rows for each of its 60 partitions, go with an Azure Database! You'll avoid the many creative solutions that Azure Data Warehouse requires to offset its unsupported table features, and stored procedures limitations Every company I work with has a different motivation for moving to Azure, and I'm surely not trying to put you into my box. The diagrams shared on my blob site change with every engagement, as no two companies have the same needs and business goals. Please allow me to encourage you to start thinking as to what your Azure Data Architecture might look like, and what your true value add talking points for a migration to Azure might be. Moving onward and upward, my technical friend, ~Delora Bradish p.s. If you have arrived at the blog post looking for a Database vs Data Warehouse, or Multidimensional vs Tabular discussion, those really are not Azure discussion points as much as they are data volume discussion points; consequently, I did not blog about these talking points here. Please contact me via www.pragmaticworks.com to schedule on site working sessions in either area.
2 Comments
When testing Azure Data Lake (ADL) to Azure Data Warehouse (ADW) file ingestion, this error continued to come up on various external table SELECTs. The confusion was that the ADL only contained parquet files. There was only one external file format defined, and that too was obviously for parquet. From where was an RCFile error originating? The bottom line, in this particular engagement scenario, was that this error is actually a truncation error.
Things to Verify:
Solution:
Supporting t-sql Scripts If you are new to PolyBase and external tables in SQL Server environments, here are a three t-sql scripts that are supporting references to the error resolution given above. Example CREATE EXTERNAL DATA SOURCE t-SQL. Click here for more information. CREATE EXTERNAL DATA SOURCE [MyDataSourceName] WITH (TYPE = HADOOP, LOCATION = N'adl://MyDataLakeName.azuredatalakestore.net', CREDENTIAL = [MyCredential]) GO Example CREATE EXTERNAL FILE FORMAT t-SQL. Click here for more information. CREATE EXTERNAL FILE FORMAT [MyFileFormatName] WITH (FORMAT_TYPE = PARQUET , DATA_COMPRESSION = N'org.apache.hadoop.io.compress.SnappyCodec') GO Example CREATE EXTERNAL TABLE t-sql script. Click here for more information. BEGIN TRY DROP EXTERNAL TABLE [ext].[MyExternalTableName] END TRY BEGIN CATCH END CATCH CREATE EXTERNAL TABLE [ext].[MyExternalTableName] ( [ColumnName1] bigint NULL ,[ColumnName2] nvarchar(4000) NULL -- if this value is too small, you will get the conversion error ,[ColumnName3] bit NULL ,[ColumnName4] datetime NULL ,[ADLcheckSum] nvarchar(64) NULL -- if this value is too small, you will get the conversion error ,[ADFIngestionId] nvarchar(64) NULL -- if this value is too small, you will get the conversion error ) WITH (DATA_SOURCE = [MyDataSourceName] , LOCATION = N'/Folder1/Folder2/' , FILE_FORMAT = [MyFileFormatName] , REJECT_TYPE = VALUE ,REJECT_VALUE = 0) GO |
 RSS Feed
RSS Feed
