|
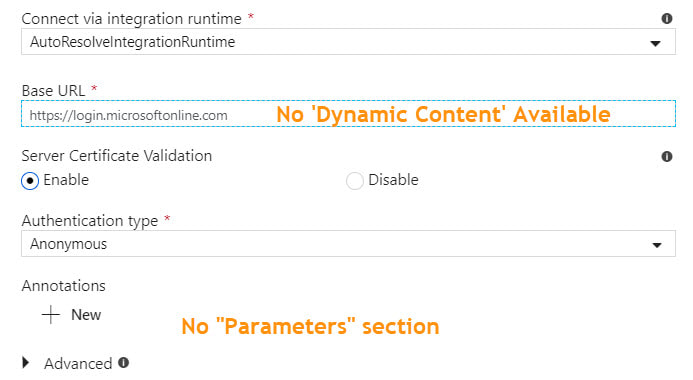
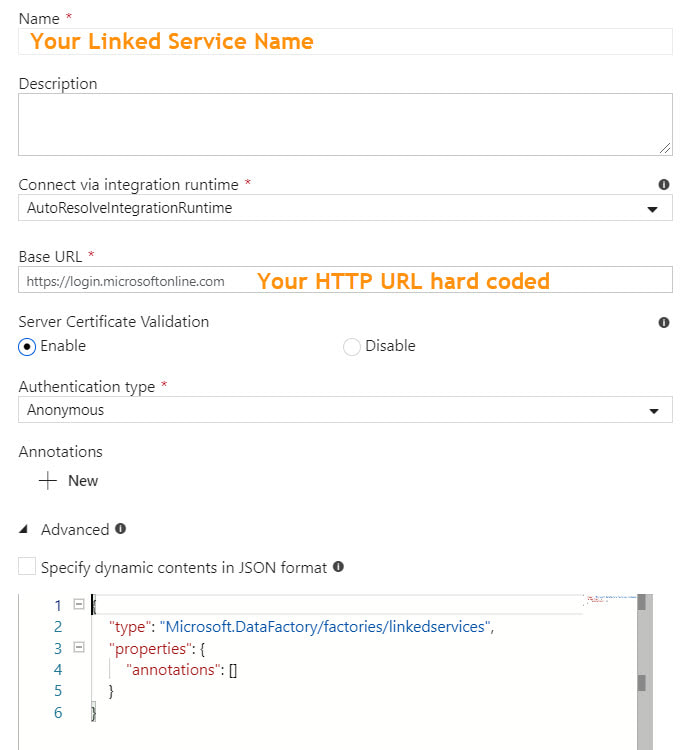
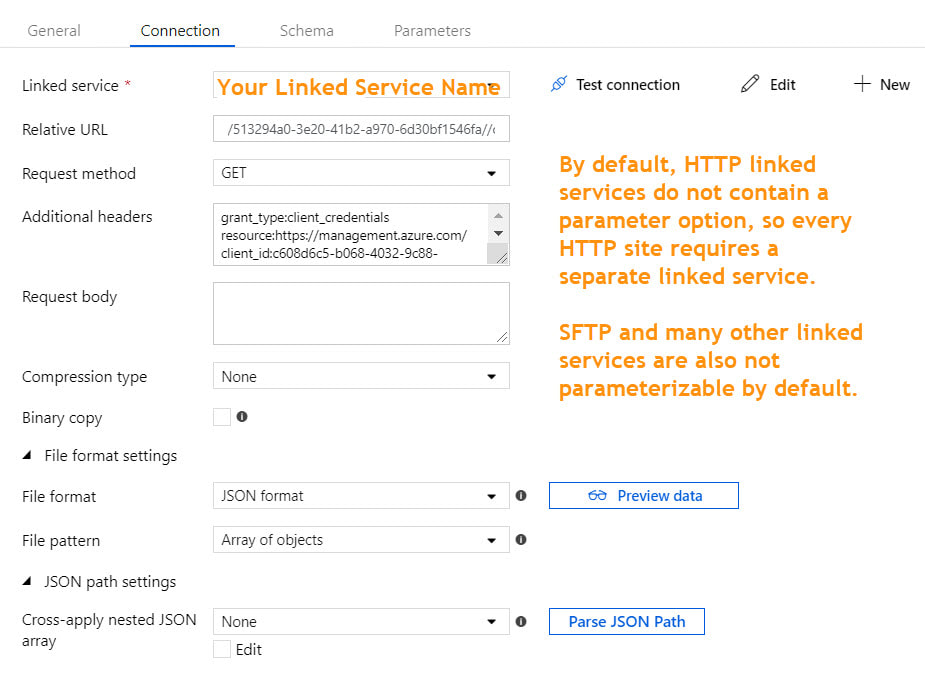
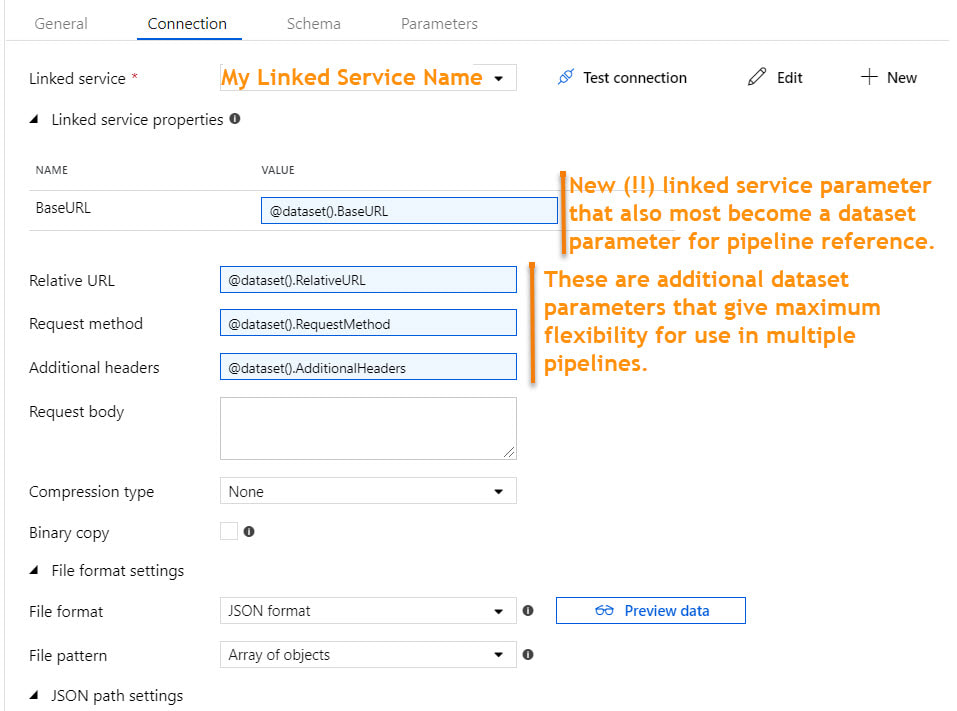
There are several linked service types that do not have built-in dynamic content in which it is possible to reference a parameter. For example, if your linked service is an Azure SQL Database, you can parameterize the server name, database name, user name, and Azure Key Vault secret name. This allows for one linked service for all Azure SQL Databases. However, if your linked service is HTTP or SFTP (or many others), there is no "dynamic content" option for key properties. This forces one linked service and one dataset for every HTTP Base URL or one linked service and dataset for every SFTP host, port and user name.
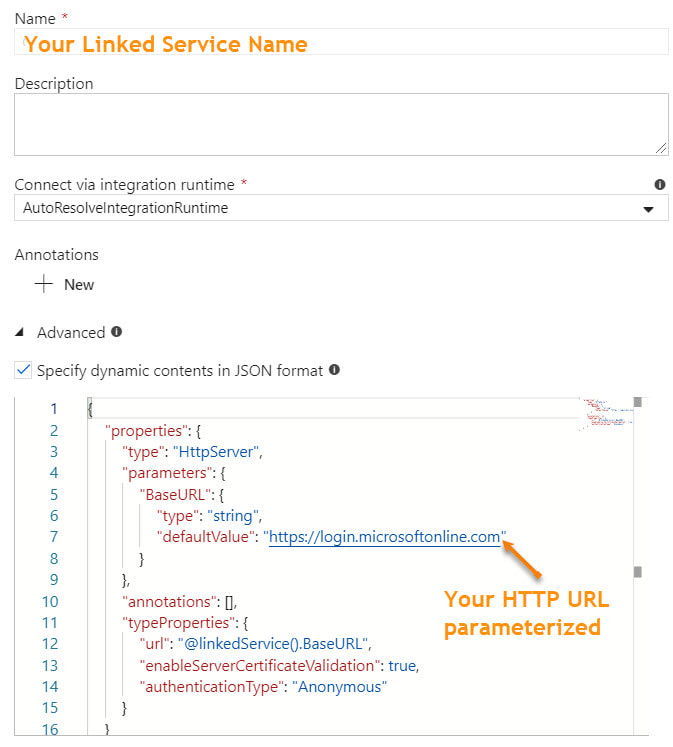
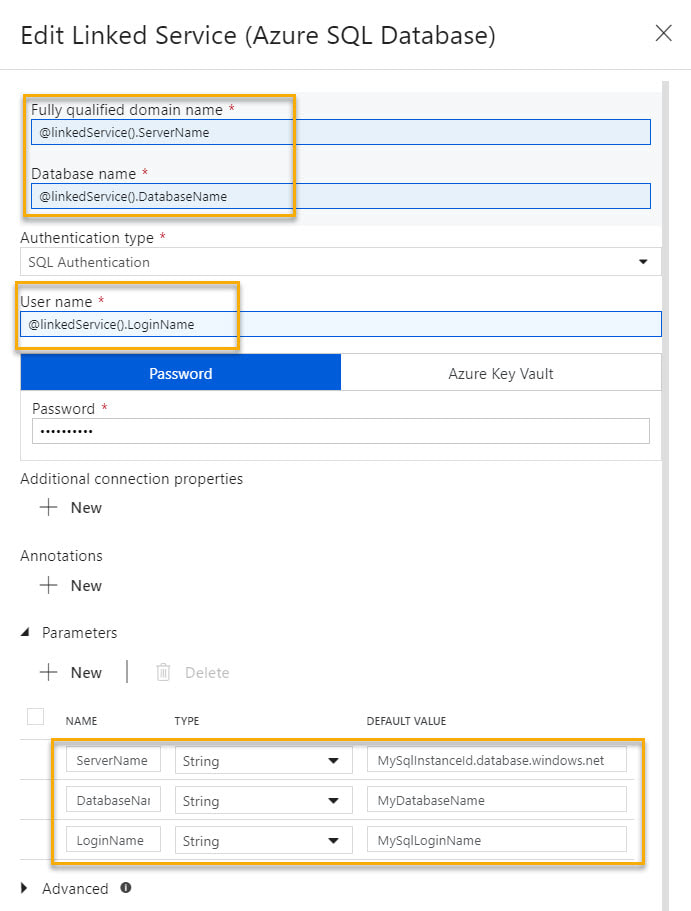
Microsoft has provided a nice solution to this problem, and it lies in the "Advanced" section of each linked service. Understanding that it is JSON syntax that sits behind the GUI of linked services, to add parameters to a linked service, we can manually modify the JSON. At this point and if this blog post were a Microsoft Doc, most of us would be scrolling down and saying, "Just show me the JSON!". Knowing this, here you go -->
***************************************************************************************************************************
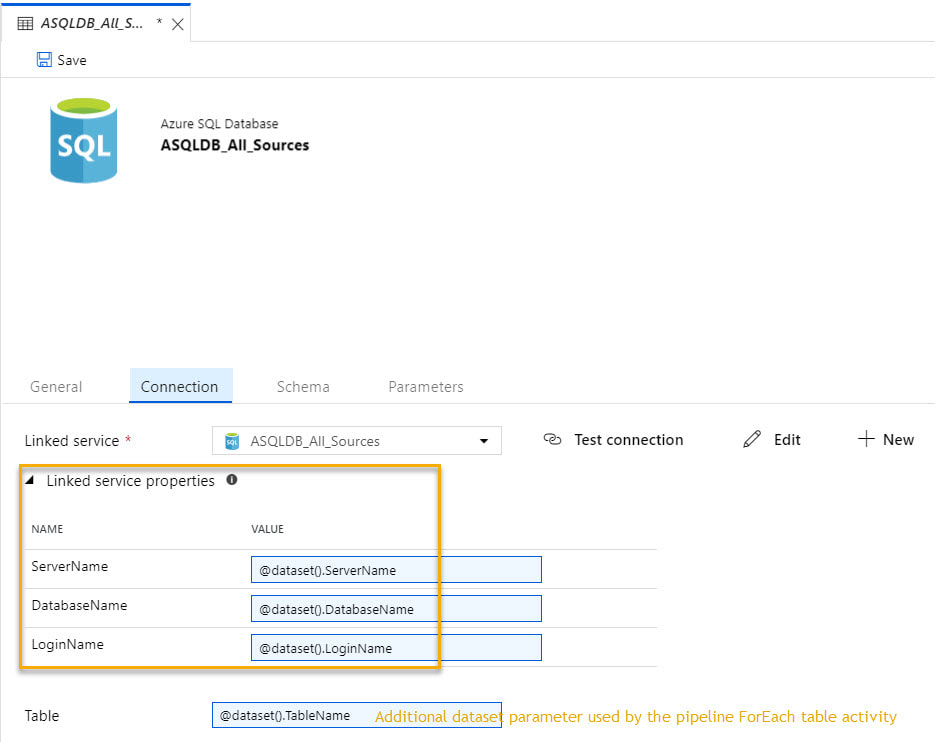
Now the question is, "How does the dataset handle this customized linked service?" I was very pleased to find that the integration of the custom JSON into a dataset was seamless.
One of the nice things about Azure Data Factory (ADFv2) is the level of parameterization now available. Until all linked service properties accept dynamic content by default, this is a nice workaround.
8 Comments
Sometimes I get so involved in my repeatable processes and project management that I forget to look up. Such is the case of the December 2018 ability to parameterize linked services. I could not rollback and rework all the ADF components this impacted which had already gone to production, but oh hooray! Moving forward, we can now have one linked service per type, one dataset per linked service and one pipeline per ingestion pattern. How sweet is that? Au revoir to the days of one SSIS package per table destination. This is blog post 3 of 3 on using parameters in Azure Data Factory (ADF). Blog post #1 was about parameterizing dates and incremental loads. Blog post #2 was about table names and using a single pipeline to stage all tables in a source. Today I am talking about parameterizing linked services. Disclaimer: Not all linked service types can be parameterized at this time. This feature only applies to eight data stores:
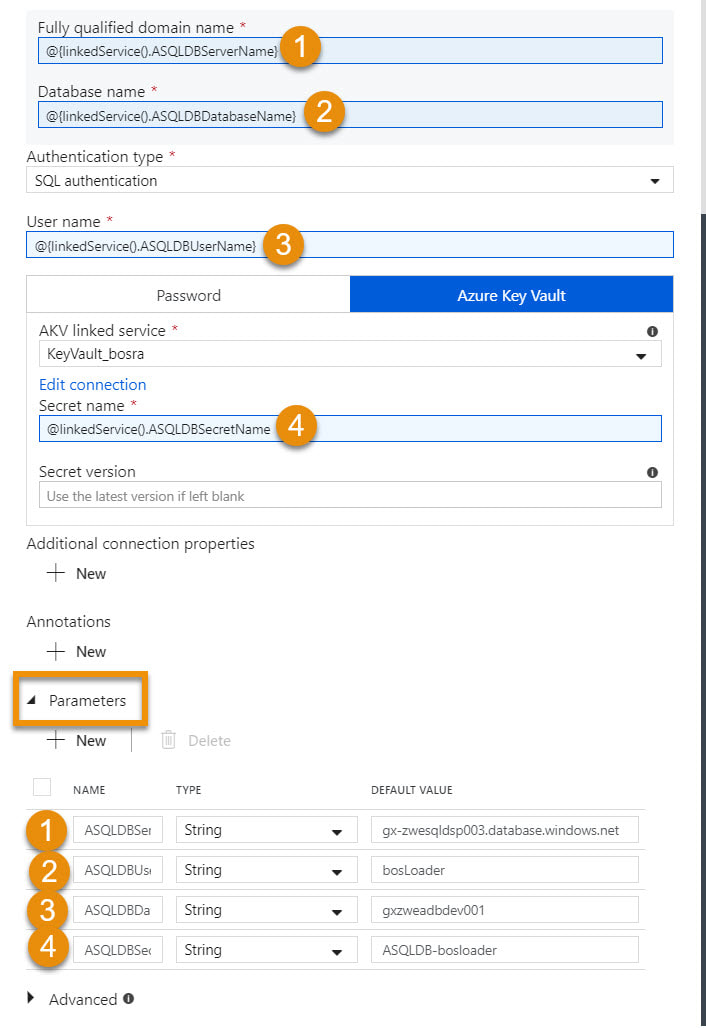
Concept Explained: The concept is pretty straightforward and if our goal is to have one linked service per type, a parameterized Azure SQL Database linked service might look like this:
Moving on the the single dataset that uses this linked service, we have the following.
Putting it all Together: 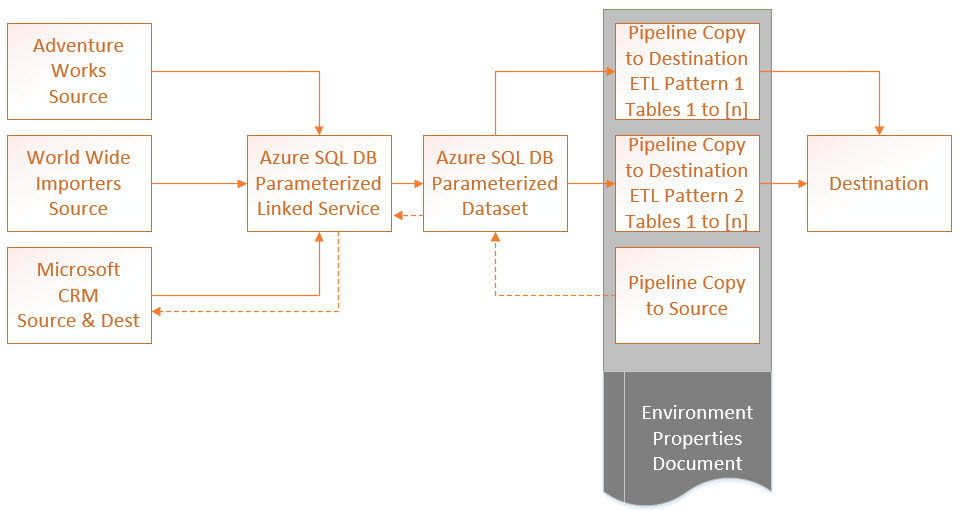 What we are after here is a repeatable process, simplicity of design, fewer developer hours, easier deployments and more efficient DevOps. We also want very little hard-coding of parameter values; thus the environment properties document. If we find that we have lost flexibility in our pipelines that are "doing to much" and a change impacts "too many destinations", rethink the parameters and kick them up a notch. Even with the above design, we should be able to execute the load of just one source, or just one table of a source. We should also be able to complete data-driven full and incremental loads with these same pipeline activities. Metadata ADF control tables and ADF orchestrator pipelines (pipelines that call other child pipelines and govern dependency), can also be helpful.
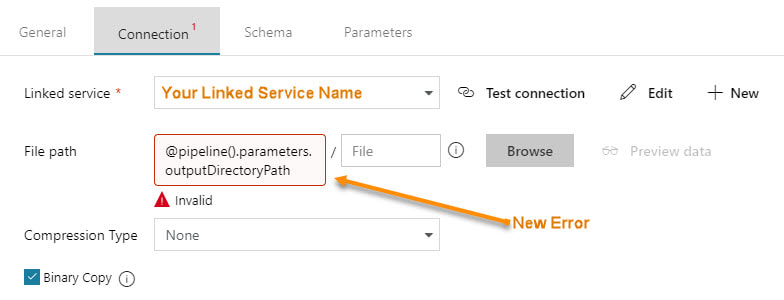
Final Musings: Obviously the above pattern works best if you are staging your data into your destination, then doing your transform and load (ELT). This brings me to a growing realization that with SSIS I had turned away from transform user stored procedures (USPs) and became disciplined in using SSIS in-memory capabilities. With a recent Azure Data Warehouse project, however, I had to renew my love of USPs. So now I am, quite frankly, betwixt and between ADF parameter capabilities for staging, Databricks performance capabilities for transforms, and our old friend, the stored procedure. For everything there is an appropriate place, so once again, let's get back to the architecture diagram and figure out what works best for your unique requirements. Summary of the Matter: Parameter passing in ADFv2 had a slight change in the summer of 2018. Microsoft modified how parameters are passed between pipelines and datasets. Prior, you could reference a pipeline parameter in a dataset without needing to create a matching dataset parameter. The screen prints below explain this much better, and if you are new to ADFv2 and parameter passing, this will give you a nice introduction. I personally feel the change is an improvement. New Warnings and Errors My client had been using ADFv2 since the beginning of 2018, then on a particular Monday, we walked into the office and noticed that our ADFv2 datasets were throwing errors and warnings.
Thankfully, Microsoft made this change backward compatible to an extent, so our pipelines were still humming merrily along. The new methodology is actually an improvement, so let's go with it! Here are the summary steps to correct the problem:
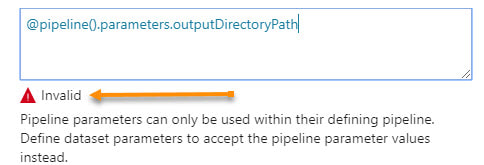
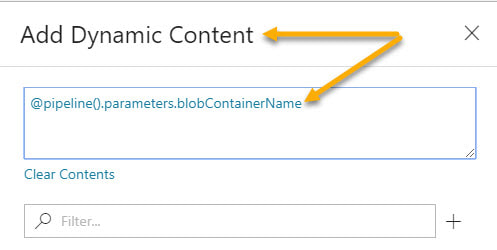
Step #1 - In the dataset, create parameter(s). 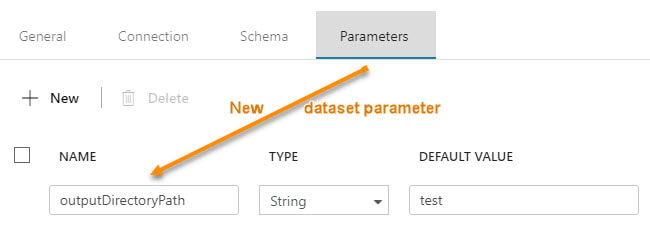 Step #2 - In the dataset, change the dynamic content to reference the new dataset parameters 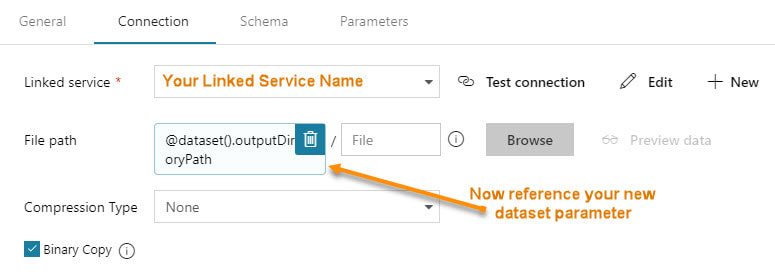 The content showing above used to read "@pipeline().parameters.outputDirectoryPath". You now have to reference the newly created dataset parameter, "@dataset().outputDirectoryPath". Step #3 - In the calling pipeline, you will now see your new dataset parameters. Enter dynamic content referencing the original pipeline parameter. 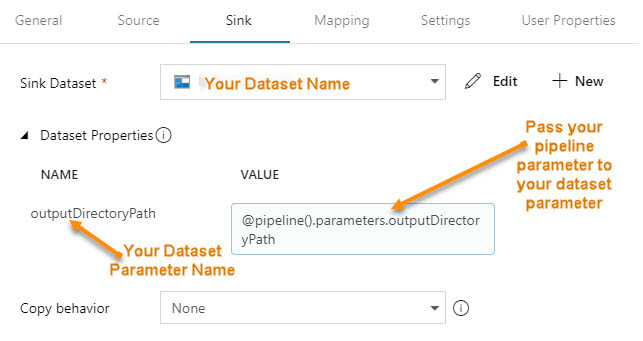 Conclusion:
The advantage is now we can explicitly pass different values to the dataset. As a dataset is an independent object and is called by a pipeline activity, referencing any sort of pipeline parameter in the dataset causes the dataset to be "orphaned". What if you want to use that dataset in a pipeline that does not have our example parameter "outputDirectoryPath"? Prior, your pipeline would fail, now you can give the dataset parameter a default inside the dataset. Better yet, your two parameter names do not have to match. In step #3, the pipeline screen print immediately above, you can put any parameter reference, system variable or function in the "VALUE". That's pretty much all there is to it! If you haven't already, start editing. In the first of three blog posts on ADFv2 parameter passing, Azure Data Factory (ADFv2) Parameter Passing: Date Filtering (blog post 1 of 3), we pretty much set the ground work. Now that I hope y'll understand how ADFv2 works, let's get rid of some of the hard-coding and make two datasets and one pipeline work for all tables from a single source. You know I have to say it ... can SSIS "show me [this] money"? This solution consists of three ADFv2 objects (yes, only three!!)
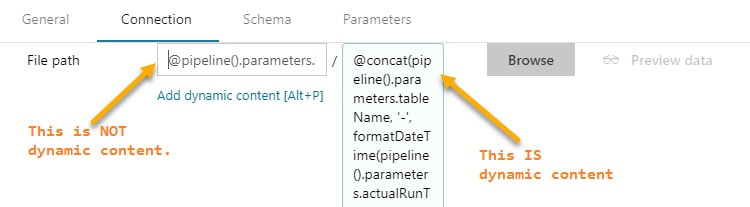
Assumption: You have read blog post 1 of 3 on parameter passing with ADFv2 and now understand the basic concept of parameter passing and concatenating values in ADFv2. Summary: This blog post builds on the first blog and will give you additional examples of how to pass a table name as dynamic content. It will show you how to use a 1.) single input dataset, 2.) single output dataset and 3.) single pipeline to extract data from all tables in a source. Setup: The JSON for all datasets and pipelines is attached below, but if you take a moment to understand the screen prints, it might be easier than reading JSON. 1. Single Input Dataset 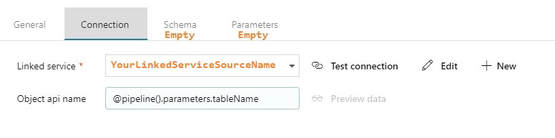 2. Single Output Dataset File path prefix --> @pipeline().parameters.blobContainerName File path suffix --> @concat(pipeline().parameters.tableName, '-', formatDateTime(pipeline().parameters.actualRunTime, 'yyyy'), formatDateTime(pipeline().parameters.actualRunTime,'MM'), formatDateTime(pipeline().parameters.actualRunTime,'dd'),' ' , formatDateTime(pipeline().parameters.actualRunTime,'hh'), formatDateTime(pipeline().parameters.actualRunTime, 'mm'), '.txt') 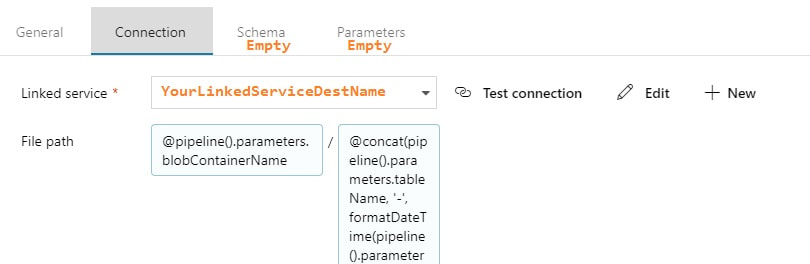 Tip: Dynamic content and text values that contain an "@pipline..." syntax are not the same thing.
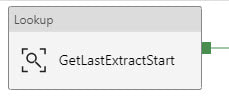
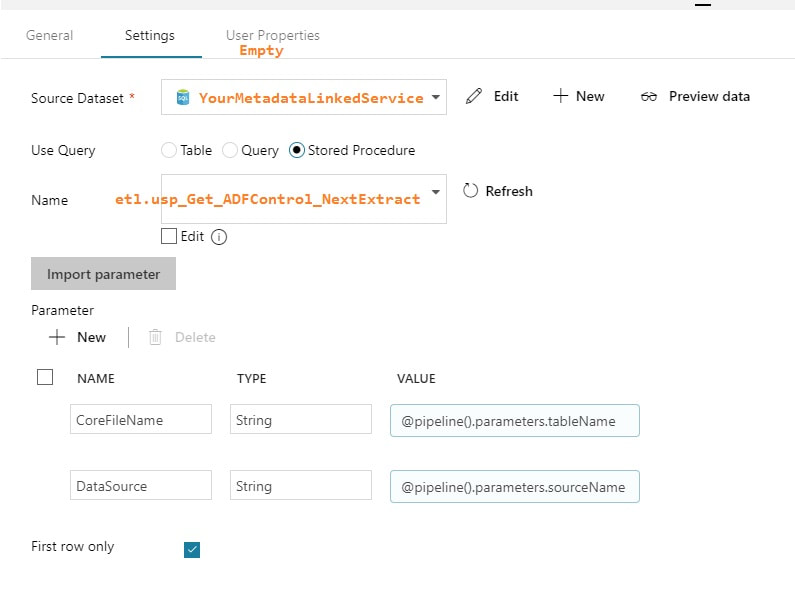
3. Single ADFv2 Pipeline The primary add-in for this blog post is the lookup for a column list and the additional parameter being used for the table name. The @pipeline().parameters.actualRunTime value is passed by an Azure Logic App not explained here, or you could use the pipeline start or a utcdate. In blog post 3 of 3 we are going to put in a ForEach loop that will allow us to spin through a list of tables.  Lookup Activity - GetLastExtractStart
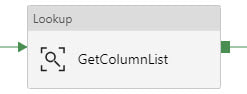
Lookup Activity -GetcolumnList
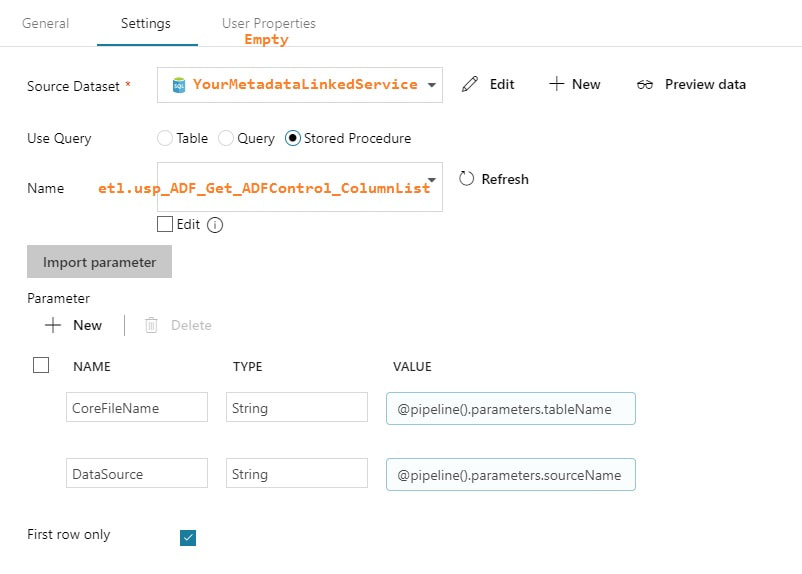
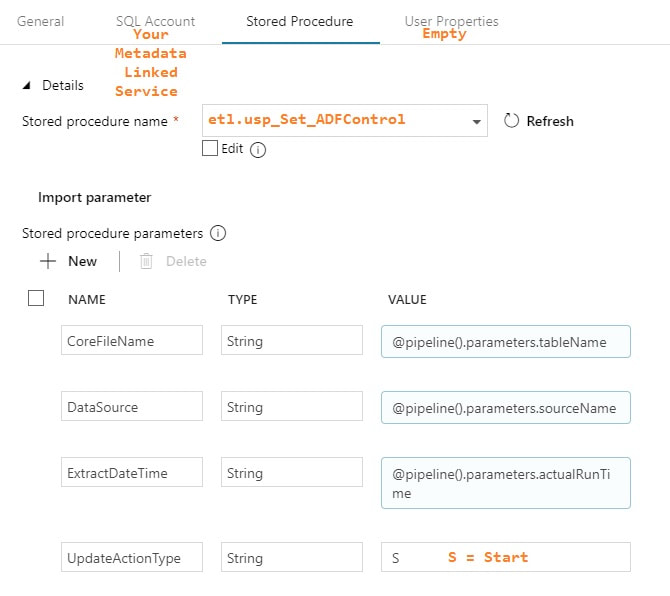
Execute Stored Procedure - SetThisExtractStart
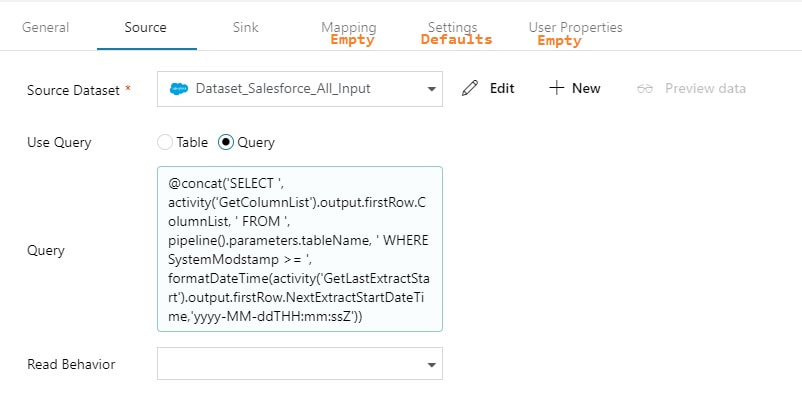
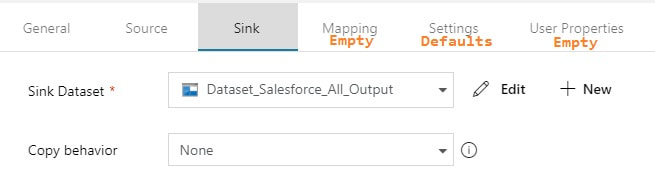
Copy Activity This is where it all comes together. You concatenate your looked up column list with your looked up table name, and now you are using a single input dataset for all source tables. 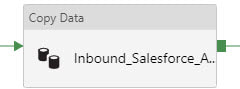 @concat('SELECT ', activity('GetColumnList').output.firstRow.ColumnList, ' FROM ', pipeline().parameters.tableName, ' WHERE SystemModstamp >= ', formatDateTime(activity('GetLastExtractStart').output.firstRow.NextExtractStartDateTime,'yyyy-MM-ddTHH:mm:ssZ'))
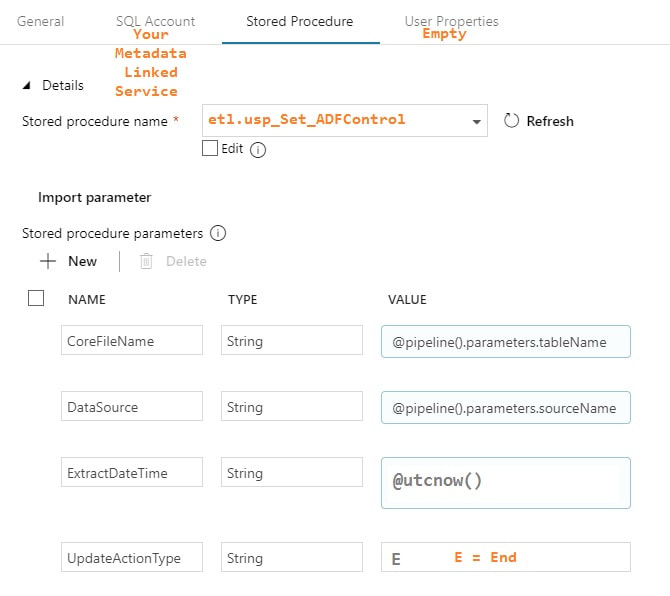
Execute Stored Procedure - SetThisExtractEnd
The Conclusion of the Matter: I've taken the time to provide all of these screen prints in loving memory of SSIS. Once you transition, you can figure most of this out with a bit of persistence, but isn't it nice to have screen prints to show you the way sometimes? The most challenging part of this is the @concat() of the source copy activity. Every data source will require this in their own syntax (SOSQL, t-sql etc.), or beware -- in the syntax of the ODBC driver that is sitting behind Microsoft's data connector. Link to Azure Data Factory (ADF) v2 Parameter Passing: Date Filtering (blog post 1 of 3) Link to Azure Data Factory (ADF) v2 Parameters Passing: Linked Services (blog post 3 of 3) Supporting Downloadable Files:
|
|||||||||||||||||||||||||||||||||||


 RSS Feed
RSS Feed
