|
Sometimes I get so involved in my repeatable processes and project management that I forget to look up. Such is the case of the December 2018 ability to parameterize linked services. I could not rollback and rework all the ADF components this impacted which had already gone to production, but oh hooray! Moving forward, we can now have one linked service per type, one dataset per linked service and one pipeline per ingestion pattern. How sweet is that? Au revoir to the days of one SSIS package per table destination. This is blog post 3 of 3 on using parameters in Azure Data Factory (ADF). Blog post #1 was about parameterizing dates and incremental loads. Blog post #2 was about table names and using a single pipeline to stage all tables in a source. Today I am talking about parameterizing linked services. Disclaimer: Not all linked service types can be parameterized at this time. This feature only applies to eight data stores:
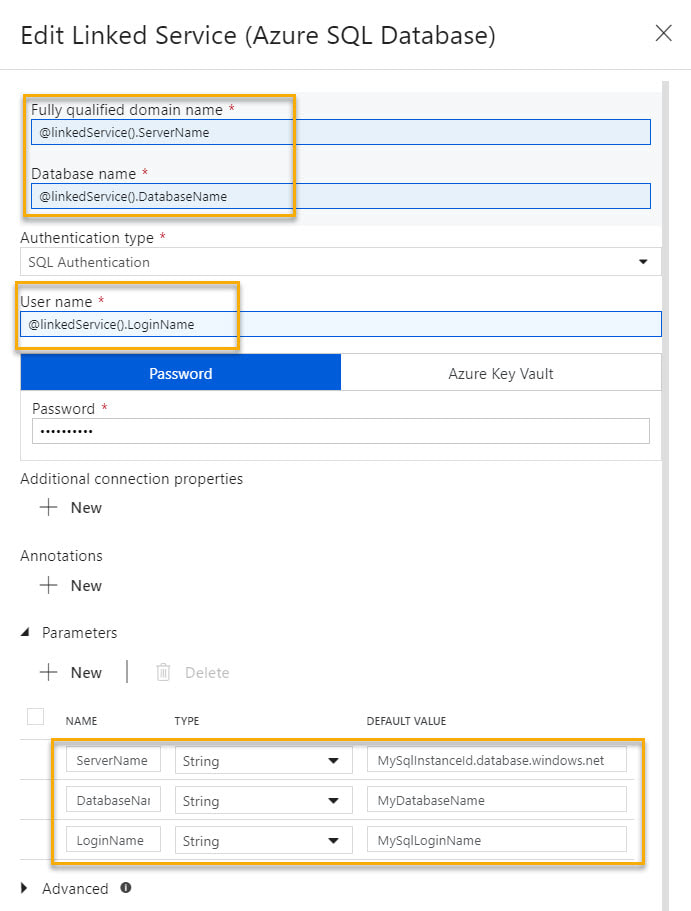
Concept Explained: The concept is pretty straightforward and if our goal is to have one linked service per type, a parameterized Azure SQL Database linked service might look like this:
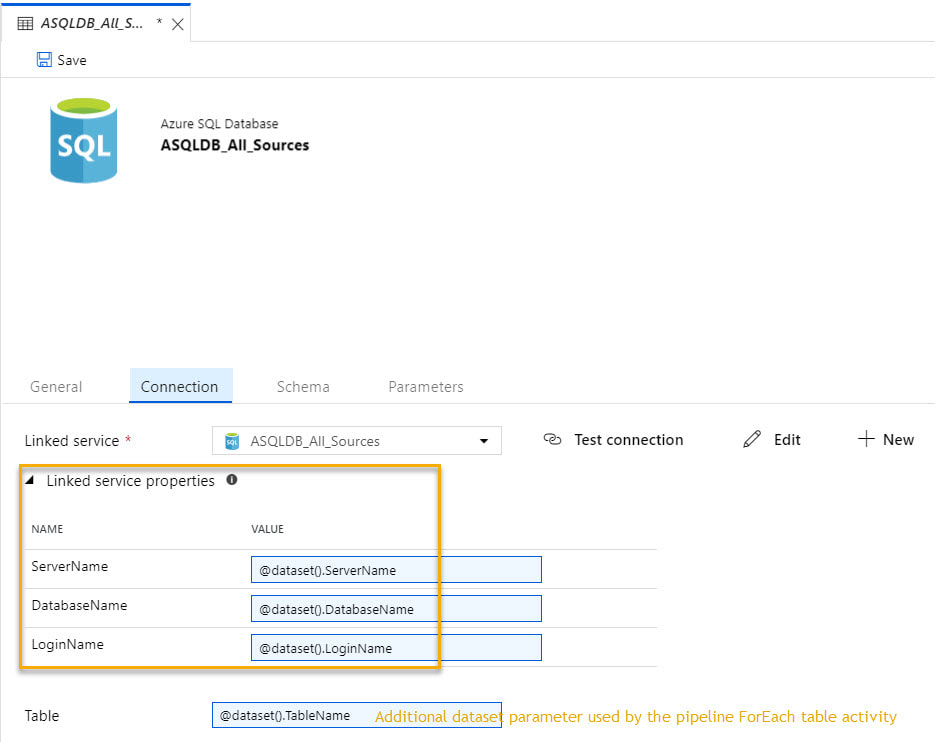
Moving on the the single dataset that uses this linked service, we have the following.
Putting it all Together: 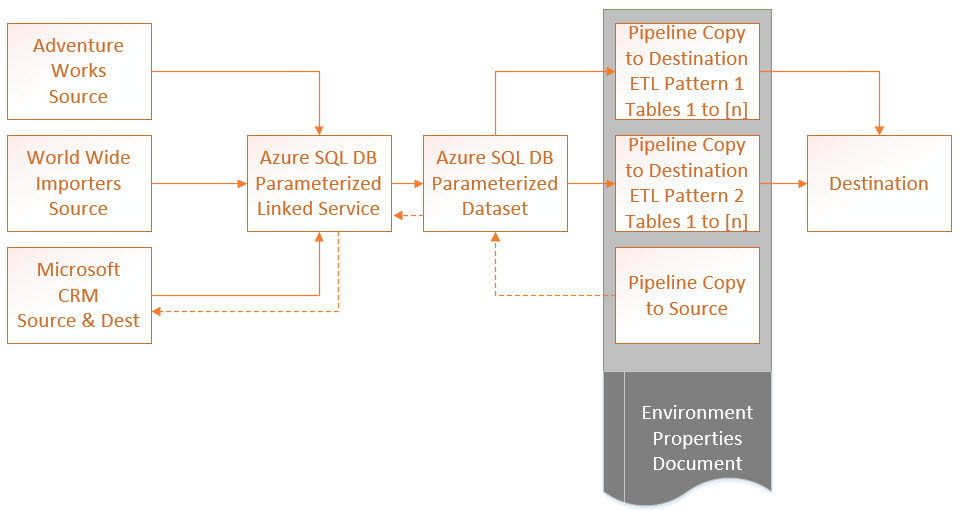 What we are after here is a repeatable process, simplicity of design, fewer developer hours, easier deployments and more efficient DevOps. We also want very little hard-coding of parameter values; thus the environment properties document. If we find that we have lost flexibility in our pipelines that are "doing to much" and a change impacts "too many destinations", rethink the parameters and kick them up a notch. Even with the above design, we should be able to execute the load of just one source, or just one table of a source. We should also be able to complete data-driven full and incremental loads with these same pipeline activities. Metadata ADF control tables and ADF orchestrator pipelines (pipelines that call other child pipelines and govern dependency), can also be helpful.
Final Musings: Obviously the above pattern works best if you are staging your data into your destination, then doing your transform and load (ELT). This brings me to a growing realization that with SSIS I had turned away from transform user stored procedures (USPs) and became disciplined in using SSIS in-memory capabilities. With a recent Azure Data Warehouse project, however, I had to renew my love of USPs. So now I am, quite frankly, betwixt and between ADF parameter capabilities for staging, Databricks performance capabilities for transforms, and our old friend, the stored procedure. For everything there is an appropriate place, so once again, let's get back to the architecture diagram and figure out what works best for your unique requirements.
1 Comment
Mike Kiser
6/19/2019 09:14:53 am
Wow! Great BLOG! This is exactly what I have to do, PLUS I have to dynamically call a Stored Proc.. I hope I can also do this with a Stored Proc. Any ideas? Thanks! Mike Leave a Reply. |

 RSS Feed
RSS Feed
