|
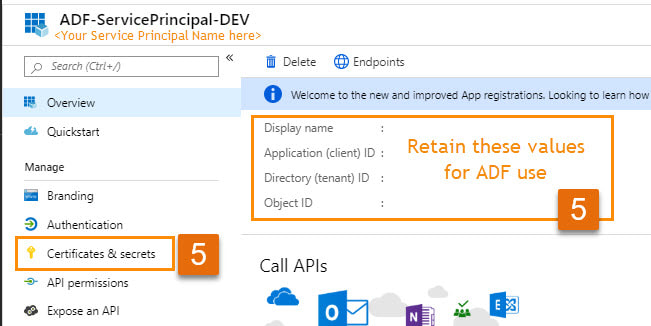
Previously I published a Quick Start Guide for avoiding concurrent pipeline executions. That was blog post 1 of 2, and I wrote it for developers familiar with Azure, especially Azure AD service principals and ADF web activities. For everyone else, I would like to provide more tips and screen prints, because if your brain works anything like mine, I put A and B together much better with a picture. When I first started with ADF and accessed Microsoft Docs, I struggled with connecting the JSON examples provided with the ADF activity UIs (user interfaces). If you had been near, you may have heard me sputtering, "what? What? WHAT??!" Enough said. This blob post will follow the same step numbers as blog post 1, so if you started with the Quick Start Guide, you can find detail for those same steps right here. Step #1: Create a service principal and record the client Id, client secret, and tenant Id for future use. When you query the ADF log, you have to impersonate someone. In ADF you do this through an Azure AD (Active Directory) application, also called a service principal. You then must give this service principal permissions in the Data Factory. If you have worked with SSIS, this is a similar concept. You run SSIS scheduled jobs as <some AD account> and that account must have permissions to your source and destinations.
Step #2: Create a file or SQL Server table to hold your environment properties. This can be a text file, SQL Server table, Cosmos DB document -- any source that can be accessed by ADF in a Lookup activity will work.
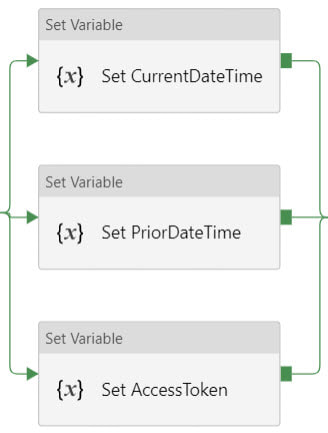
 Step #3: Create a new pipeline with parameters and variables.
Step #4: Add a Lookup activity to the pipeline named "Get Environment Properties" If you used my SQL Server metadata script above, your lookup activity properties will look similar to the next screen print. To read the data values stored in memory, ADF syntax would be @activity('Get environment Properties').output.firstRow.YourColumnName. 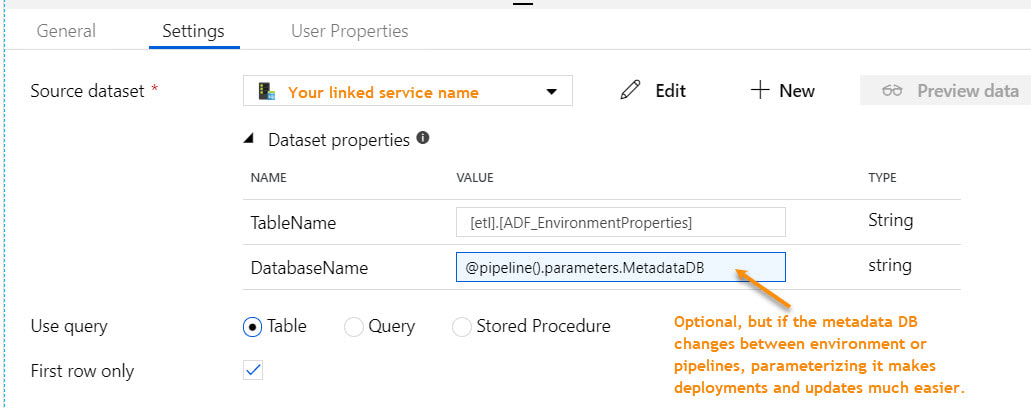
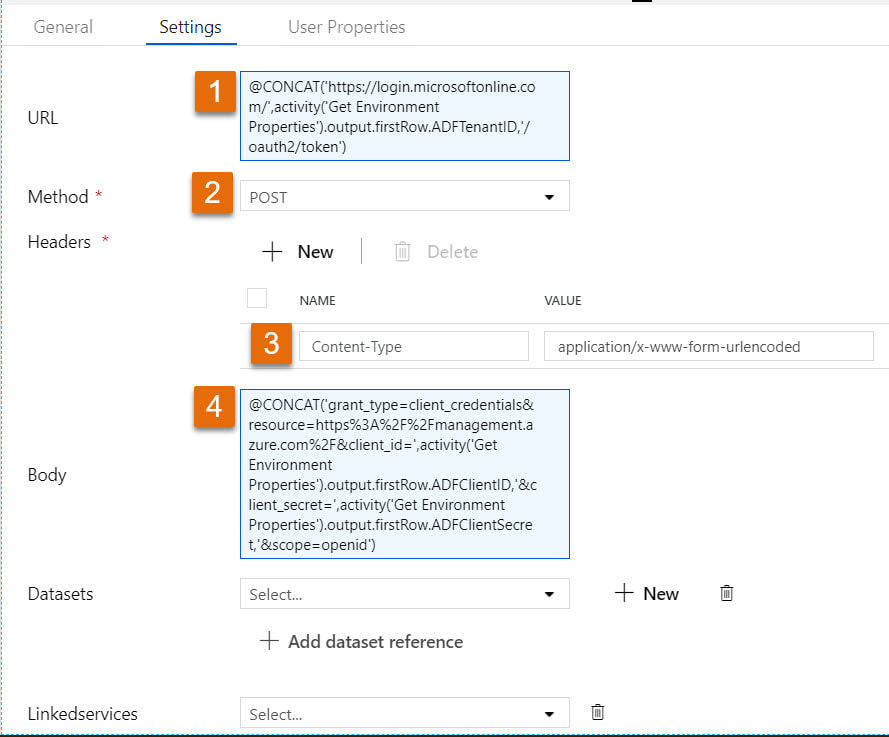
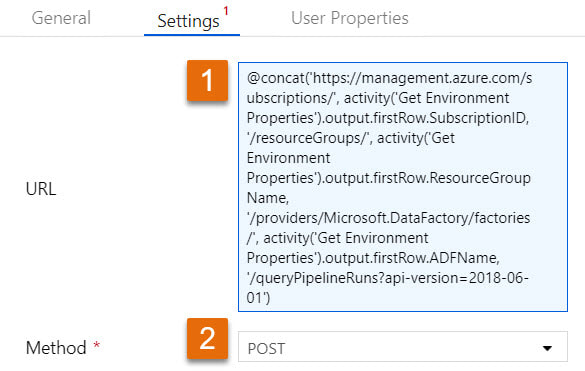
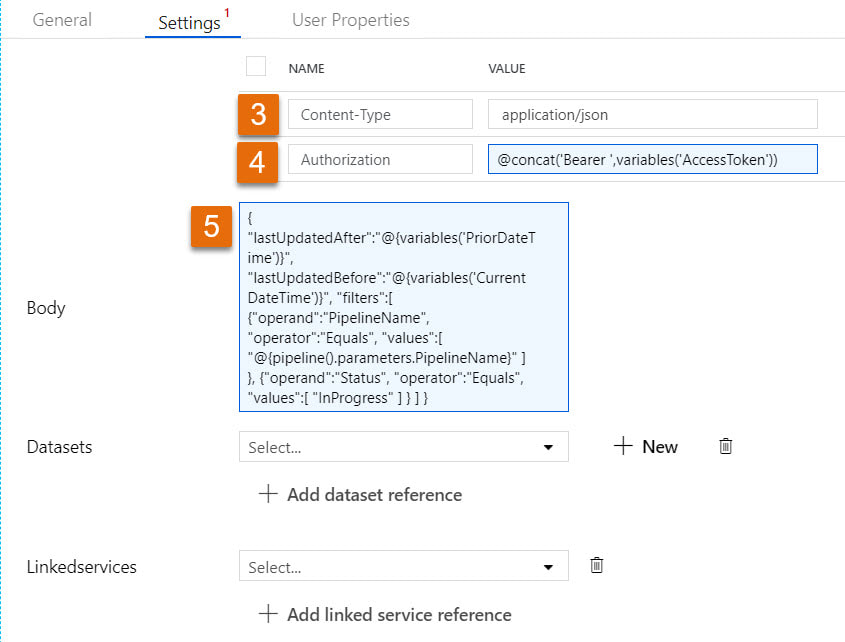
Step #7: Add a second web activity to the pipeline named "Get ADF Execution Metadata" Syntax for this activity is provided in the Microsoft Doc here, but because the documentation leaves so much to the imagination (isn't that a nice way of saying it?), follow the screen prints and copy the syntax provided below. 1 - @concat('https://management.azure.com/subscriptions/', activity('Get Environment Properties').output.firstRow.SubscriptionID, '/resourceGroups/', activity('Get Environment Properties').output.firstRow.ResourceGroupName, '/providers/Microsoft.DataFactory/factories/', activity('Get Environment Properties').output.firstRow.ADFName, '/queryPipelineRuns?api-version=2018-06-01') 3 - application/json 4 - @concat('Bearer ',variables('AccessToken')) 5 - { "lastUpdatedAfter":"@{variables('PriorDateTime')}", "lastUpdatedBefore":"@{variables('CurrentDateTime')}", "filters":[ {"operand":"PipelineName", "operator":"Equals", "values":[ "@{pipeline().parameters.PipelineName}" ] }, {"operand":"Status", "operator":"Equals", "values":[ "InProgress" ] } ] }
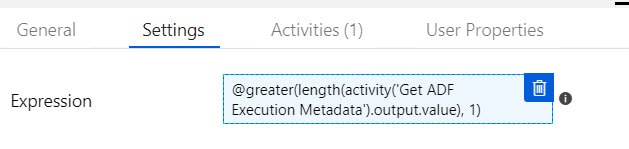
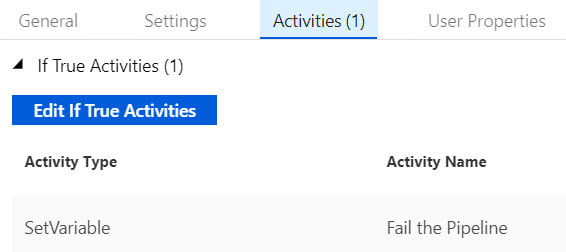
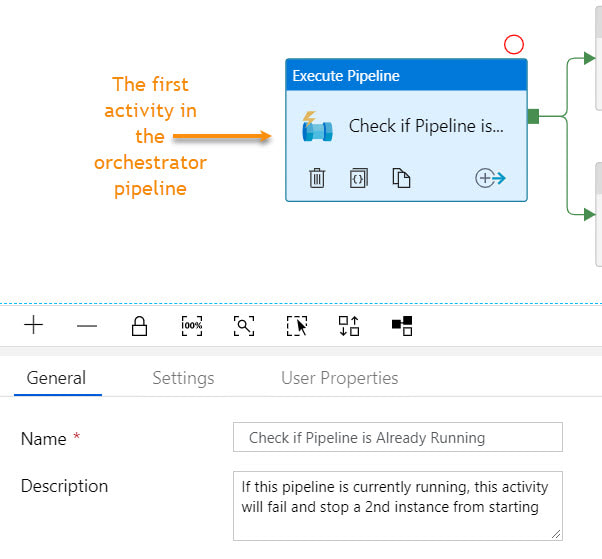
Step #10: Connect the pipeline activities all with green Success arrows. I am including a screen shot of the completed pipeline so that you have a visual of how everything comes together. 
Conclusion of the Matter: I admire people who can wax eloquent about Azure theory and great ideas. Being a Microsoft tool stack mentor and consultant, I simply do not feel prepared unless I can say "I have a POC for that!" I think of this as a "show me the money!" training technique. This is exactly why I have just written a entire chapter in two blog posts. Friend, "this is the money". Go forth and query your ADF pipeline run metadata with confidence!
4 Comments
Jason
8/25/2021 08:46:10 am
This is extremely helpful. Thank you so much. I found two things when following the post.
Lokesh N
10/11/2021 08:07:21 am
Thank you very much. Will try this ! 5/4/2022 10:14:11 pm
Hi Team, well made sense of about Azure Data Factory (ADF) Pipeline Runs - Query By Factory and Avoid Concurrent Pipeline Execution. Much obliged for your significant blog by your Team!! 5/24/2022 08:06:38 am
Your Article is really impressive about Azure Data Factory (ADF) Pipeline Runs - Query By Factory & Avoid Concurrent Pipeline Executions. very clear and effective by simple steps Leave a Reply. |



 RSS Feed
RSS Feed
