|
At the bottom of this blog post you will find the ZIP file referenced in today's webinar from Pragmatic Works. Webinar Talking Points: 1. SSAS Performance Optimization 10K Foot View 2. Profiler vs Extended Events 3. SQL Server Instance QueryLog Properties 4. SQL Server 2016 Profiler & Extended Events Demos 5. Interpreting Extended Events Data 6. Extended Events Integration with SSIS Demo ZIP File Contents: 1. Slide deck in PDF format with and without notes 2. XMLA scripts for creating, stopping, deleting extended events. (Also find these files here.) 3. T-SQL scripts for interpreting SSAS event data. (Also find these files here.) 4. Visual Studio Community Edition SSIS solution for warming multidimensional cache Thanks for coming!!
1 Comment
Extended Events (EE) is a great SQL Server tool for monitoring Analysis Services, both multidimensional and tabular models. I use EE primarily to answer five questions about SSAS. 1. Who is actually using our tabular models and multidimensional cubes? 2. How often is [someone] running queries? 3. What are my longest running queries? 4. For multidimensional cubes, and I missing aggregations? 5. For long-running queries, is the problem my storage or formula engine? I also like to use EE to warm the multidimensional cache after cube processing, but that is a subject for another blog post. The subject of this blog post is really about interpreting data captured by EE. Prerequisite: Knowledge of how to start, stop and import data from EE sessions. If EEs are new to you, I have a blog post on EE for Analysis Services Database Administration that might be helpful. This blog post assumes that you have already imported EE data into a SQL Server database table and are at the point of wanting to analyze that data. Summary: If you want to jump to the finish line, download the two files I've attached to this blog post. They are t-sql statements that read from EE SQL Server tables for both multidimensional and tabular models returning login, query durations, execution counts, storage and formula engine durations. Enjoy! Detail: The most important thing to understand when reading EE data is how EE reports storage and formula engine durations. Very simplistically, the storage engine is exactly what you think it is -- it stores the data. The formula engine does the number crunching. The first step in SSAS query optimization is to understand where you are paying the price of the query duration. Multidimensional Cubes  Tabular Models  The attached t-sql documents have this all figured out for you, but I fully expect you to take these code samples and make them your own. For example, group the resulting row set ordering by QueryDuration DESC, or select for one particular user Id. Compare the storage and formula engine durations and email a SSRS report for percentages exceeding a predetermined amount. Basically, use EE to be proactive in finding long-running queries and don't wait for the help desk phone to ring. If working with multidimensional cubes, pay attention to the QuerySubcubeVerbose event. The query text will help you identify missing aggregations. Expert Cube Development with Multidimensional Models will give you more information on this. My experience has been that once I make sure all necessary hierarchies are in place, all fact tables are partitioned properly, aggregations have updated with usage-based aggregations, and poorly written MDX has been revised, I rarely have to spend time in the QuerySubcubeVerbose event. However, as a matter of last resort, this event has much complicated but informative query information. Files for Download
As a SSAS DBA, or even as a SSAS developer who has responsibility for partition file sizes and multidimensional cube performance considerations, knowing the actual file size of partitions on disc is critical. This is not 'estimated size' that you will get from $system.discover_partition_stat, that is reflected in SSMS (SQL Server Management Studio) properties, or is found in the Visual Studio project source code. I am talking about actual file size on physical disc. I recently posted a blog with source code that provides t-SQL to get actual aggregation file size on disc. With a little updating, you can use the same script to get patition file sizes. Note: Partition sizes should be at least 4 GB in size. Smaller, larger or unbalanced partitions sizes and you are risking increasing query response times and query processing. I hear there is a blog post showing how to get this information in Excel, but I'm a t-SQL girl and I want to use SSMS to get my cube metadata. The output of the t-SQL statement I am providing is what you see here, but with your cube and partition names: 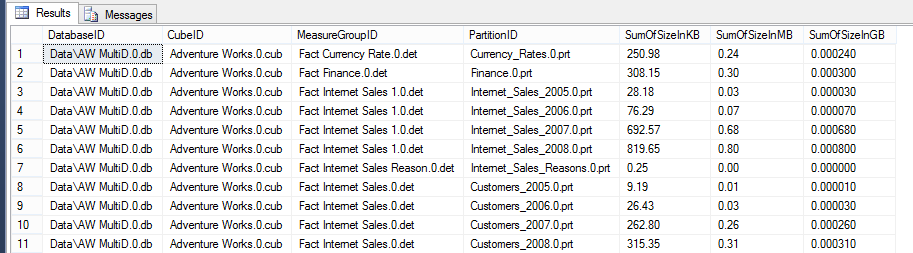
If you are unable to download the above t-SQL file, I am pasting the source code here, but my blog service provider doesn't always format it as nicely as SSMS.
Enjoy! /* Script written by Delora J Bradish, www.delorabradish.com Script snippet taken from http://stackoverflow.com/questions/7952406/get-each-file-size-inside-a-folder-using-sql as indicated below To use: 1. Change the @i_DataFileLocation to the folder location of your SSAS MultiD cube data If you don't know where this is, look under [Your SSAS Instance] --> Properties --> General --> DataDir 2. Change the @i_DatabaseId to be your database Id. This is NOT the database name. Find you database Id by looking under [Your SSAS Instance] --> [Your Deployed Database Name] --> Properties --> Database --> ID 3. Change the @i_CubeId to be your cube Id. This is NOT the cube name. Find your cube Id by looking under [Your SSAS Instance] --> [Your SSAS Database Name] --> [Your Cube Name] --> Properties --> General -> ID 4. Set @lPrintIt to one (1) to see the detail data extracted behind the final output 4. Make sure xp_cmdshell is enabled on your SQL Server Database instance. You will need to be a sysadmin on your DB instance to run this t-SQL. -- To allow advanced options to be changed. EXEC sp_configure 'show advanced options', 1 GO -- To update the currently configured value for advanced options. RECONFIGURE GO -- To enable the feature. EXEC sp_configure 'xp_cmdshell', 1 GO -- To update the currently configured value for this feature. RECONFIGURE GO 5. You will need to have read access to the physical drives where your SSAS data is stored. Use Windows File Explorer and make sure your AD account can navigate to and see *.db, *.cub, *.det, and *.prt files. Note: If you receive blank output from these SELECT statements, chances are the values entered in the input variables are incorrect. If you do not recognize the PartitionID values, you may want to drop and recreate your partitions so that their IDs match their names */ DECLARE @i_DataFileLocation varchar(max) = 'C:\PW_DEV\SQL Server\MSSQL\OLAP\' , @i_DatabaseId varchar(500) = '%AW MultiD%' , @i_CubeId varchar(100) = '%Adventure Works%' DECLARE @lCnt int, @lComm varchar(1000), @lResultString varchar(max), @lPrintIt int, @lSuccess int, @CurrentDirectory varchar(1000), @1MB DECIMAL, @1KB DECIMAL SELECT @lPrintIt = 0, @lSuccess = 0, @1MB = 1024 * 1024, @1KB = 1024 --drop temp tables if they already exist IF OBJECT_ID(N'tempdb..#DataFileList') IS NOT NULL DROP table #DataFileList IF OBJECT_ID(N'tempdb..#tempFilePaths') IS NOT NULL DROP TABLE #tempFilePaths IF OBJECT_ID(N'tempdb..#tempFileInformation') IS NOT NULL DROP TABLE #tempFileInformation IF OBJECT_ID(N'tempdb..#FinalOutput') IS NOT NULL DROP TABLE #FinalOutput -- Create the temp table that will hold the data file names CREATE TABLE #DataFileList(DataFileName varchar(max)) IF @@error <> 0 SELECT @lResultString = '1.a Unable to create #DataFileList' CREATE TABLE #tempFilePaths (Files VARCHAR(500)) IF @@error <> 0 SELECT @lResultString = '1.a Unable to create #tempFilePaths' CREATE TABLE #tempFileInformation (FilePath VARCHAR(500), FileSize VARCHAR(100)) IF @@error <> 0 SELECT @lResultString = '1.a Unable to create #tempFileInformation' CREATE TABLE #FinalOutput (FullPathAndFile varchar(400), NameOfFile VARCHAR(400), SizeInMB DECIMAL(13,2), SizeInKB DECIMAL(13,2)) IF @@error <> 0 SELECT @lResultString = '1.a Unable to create #FinalOutput' --get the list of data files SELECT @lComm = 'dir "' + @i_DataFileLocation + '*.data*" /b /s' INSERT #DataFileList EXEC master..xp_cmdshell @lComm --Clean up the list DELETE FROM #DataFileList WHERE DataFileName NOT LIKE '%string.data%' AND DataFileName NOT LIKE '%fact.data%' DELETE FROM #DataFileList WHERE DataFileName NOT LIKE '%.prt\%' OR DataFileName LIKE '%.agg.%' or DataFileName is NULL IF @lPrintIt = 1 SELECT * FROM #DataFileList --add an identity seed for remaining rows to use in WHILE loop ALTER TABLE #DataFileList ADD RowNum int Identity(1,1) --loop through DataFileName values and get file size -- from http://stackoverflow.com/questions/7952406/get-each-file-size-inside-a-folder-using-sql SET @lcnt = (select count(*) from #DataFileList) WHILE @lcnt <> 0 BEGIN BEGIN DECLARE @filesize INT SET @CurrentDirectory = (SELECT DataFileName FROM #DataFileList WHERE RowNum = @lcnt) SET @lcomm = 'dir "' + @CurrentDirectory +'"' ------------------------------------------------------------------------------------------ -- Clear the table DELETE FROM #tempFilePaths INSERT INTO #tempFilePaths EXEC MASTER..XP_CMDSHELL @lcomm --delete all directories DELETE #tempFilePaths WHERE Files LIKE '%<dir>%' --delete all informational messages DELETE #tempFilePaths WHERE Files LIKE ' %' --delete the null values DELETE #tempFilePaths WHERE Files IS NULL --get rid of dateinfo UPDATE #tempFilePaths SET files =RIGHT(files,(LEN(files)-20)) --get rid of leading spaces UPDATE #tempFilePaths SET files =LTRIM(files) --split data into size and filename ---------------------------------------------------------- -- Clear the table DELETE FROM #tempFileInformation; -- Store the FileName & Size INSERT INTO #tempFileInformation SELECT RIGHT(files,LEN(files) -PATINDEX('% %',files)) AS FilePath, LEFT(files,PATINDEX('% %',files)) AS FileSize FROM #tempFilePaths -------------------------------- -- Remove the commas UPDATE #tempFileInformation SET FileSize = REPLACE(FileSize, ',','') -------------------------------------------------------------- -- Store the results in the output table -------------------------------------------------------------- INSERT INTO #FinalOutput (FullPathAndFile, NameOfFile, SizeInMB, SizeInKB) SELECT @CurrentDirectory, FilePath, CAST(CAST(FileSize AS DECIMAL(13,2))/ @1MB AS DECIMAL(13,2)), CAST(CAST(FileSize AS DECIMAL(13,2))/ @1KB AS DECIMAL(13,2)) FROM #tempFileInformation -------------------------------------------------------------------------------------------- Set @lcnt = @lcnt -1 END END ALTER TABLE #FinalOutput ADD DatabaseID varchar(500) ,CubeID varchar(500) ,MeasureGroupID varchar(500) ,PartitionID varchar(500) /* --Run the following script for trouble shooting undesired output SELECT * ,(CHARINDEX('.det\',FullPathAndFile,1)) as EndHere ,(CHARINDEX('.cub\',FullPathAndFile,1)) as StartHere ,(CHARINDEX('.prt\',FullPathAndFile,1) + 4) - (CHARINDEX('.det\',FullPathAndFile,1) + 5) ,SUBSTRING(FullPathAndFile,CHARINDEX('.det\',FullPathAndFile,1) + 5,25) ,SUBSTRING(FullPathAndFile,CHARINDEX('.det\',FullPathAndFile,1) + 5,(CHARINDEX('.prt\',FullPathAndFile,1) + 4) - (CHARINDEX('.det\',FullPathAndFile,1) + 5)) FROM #FinalOutput */ UPDATE #FinalOutput SET DatabaseID = SUBSTRING(FullPathAndFile,LEN(@i_DataFileLocation) + 1,CHARINDEX('.db\',FullPathAndFile,1) - LEN(@i_DataFileLocation) + 2) ,CubeID = SUBSTRING(FullPathAndFile,CHARINDEX('.db\',FullPathAndFile,1) + 4,CHARINDEX('.cub\',FullPathAndFile,1) - CHARINDEX('.db\',FullPathAndFile,1)) ,MeasureGroupID = SUBSTRING(FullPathAndFile,CHARINDEX('.cub\',FullPathAndFile,1) + 5,CHARINDEX('.det\',FullPathAndFile,1) - CHARINDEX('cub\',FullPathAndFile,1)) ,PartitionID = SUBSTRING(FullPathAndFile,CHARINDEX('.det\',FullPathAndFile,1) + 5,(CHARINDEX('.prt\',FullPathAndFile,1) + 4) - (CHARINDEX('.det\',FullPathAndFile,1) + 5)) IF @lPrintIt = 1 SELECT * FROM #FinalOutput WHERE DatabaseID like @i_DatabaseId --get total partition sizes on disc select DatabaseID ,CubeID ,MeasureGroupID ,PartitionID ,SumOfSizeInKB = SUM(SizeInKB) ,SumOfSizeInMB = SUM(SizeInMB) ,SumOfSizeInGB = SUM(SizeInMB) / 1000 FROM #FinalOutput WHERE DatabaseID like @i_DatabaseId AND CubeID like @i_CubeId GROUP BY DatabaseID, CubeID, MeasureGroupID, PartitionID ORDER BY DatabaseID, CubeID, MeasureGroupID, PartitionID RETURN I recently posted a blog with source code that provides t-SQL to get actual partition file size on disc. With a little updating, you can use the same script to get aggregation file sizes. Why do we care? 1. Aggregations are a shortcut to acquiring a SUM() or a COUNT() of a measure. Think of aggregations as pre-calculated totals. 2. Correctly designed aggregations have a direct and SIGNIFICANT influence on end-user query performance. 3. Aggregations are not automatic. You must create them in the cube on the Aggregations tab, and as a general rule of thumb, aggregations should not exceed 30% of partition size. 4. Monitoring partition and aggregation file sizes is an on-going effort and it is often the place where multidimensional cubes "fall down" -- no one is paying attention. Developers move on to new projects, and even large companies often do not have dedicated SSAS DBAs. However, this can be an easy win if given an Outlook calendar reminder and a little effort. Reminder: Each partition can only have one (1) active aggregation design; however, because a measure group can have > 1 partition, measure groups can have > 1 aggregation design. The output of the t-SQL statement I am providing is what you see here, but with your cube and partition names: 
If you are unable to download the above t-SQL file, I am pasting the source code here, but my blog service provider doesn't always format it as nicely as SSMS.
Enjoy! /* Script written by Delora J Bradish, www.delorabradish.com Script snippet taken from http://stackoverflow.com/questions/7952406/get-each-file-size-inside-a-folder-using-sql as indicated below To use: 1. Change the @i_DataFileLocation to the folder location of your SSAS MultiD cube data If you don't know where this is, look under [Your SSAS Instance] --> Properties --> General --> DataDir 2. Change the @i_DatabaseId to be your database Id. This is NOT the database name. Find you database Id by looking under [Your SSAS Instance] --> [Your Deployed Database Name] --> Properties --> Database --> ID 3. Change the @i_CubeId to be your cube Id. This is NOT the cube name. Find your cube Id by looking under [Your SSAS Instance] --> [Your SSAS Database Name] --> [Your Cube Name] --> Properties --> General -> ID 4. Set @lPrintIt to one (1) to see the detail data extracted behind the final output 4. Make sure xp_cmdshell is enabled on your SQL Server Database instance. You will need to be a sysadmin on your DB instance to run this t-SQL. -- To allow advanced options to be changed. EXEC sp_configure 'show advanced options', 1 GO -- To update the currently configured value for advanced options. RECONFIGURE GO -- To enable the feature. EXEC sp_configure 'xp_cmdshell', 1 GO -- To update the currently configured value for this feature. RECONFIGURE GO 5. You will need to have read access to the physical drives where your SSAS data is stored. Use Windows File Explorer and make sure your AD account can navigate to and see *.db, *.cub, *.det, and *.prt files. Note: If you receive blank output from these SELECT statements, chances are the values entered in the input variables are incorrect. If you do not recognize the PartitionID values, you may want to drop and recreate your partitions so that their IDs match their names Remember that SSAS only allows one (1) active aggregation design for each partition. */ DECLARE @i_DataFileLocation varchar(max) = 'C:\PW_DEV\SQL Server\MSSQL\OLAP\' , @i_DatabaseId varchar(500) = '%AW MultiD%' , @i_CubeId varchar(100) = '%Adventure Works%' DECLARE @lCnt int, @lComm varchar(1000), @lResultString varchar(max), @lPrintIt int, @lSuccess int, @CurrentDirectory varchar(1000), @1MB DECIMAL, @1KB DECIMAL SELECT @lPrintIt = 0, @lSuccess = 0, @1MB = 1024 * 1024, @1KB = 1024 --drop temp tables if they already exist IF OBJECT_ID(N'tempdb..#DataFileList') IS NOT NULL DROP table #DataFileList IF OBJECT_ID(N'tempdb..#tempFilePaths') IS NOT NULL DROP TABLE #tempFilePaths IF OBJECT_ID(N'tempdb..#tempFileInformation') IS NOT NULL DROP TABLE #tempFileInformation IF OBJECT_ID(N'tempdb..#FinalOutput') IS NOT NULL DROP TABLE #FinalOutput -- Create the temp table that will hold the data file names CREATE TABLE #DataFileList(DataFileName varchar(max)) IF @@error <> 0 SELECT @lResultString = '1.a Unable to create #DataFileList' CREATE TABLE #tempFilePaths (Files VARCHAR(500)) IF @@error <> 0 SELECT @lResultString = '1.a Unable to create #tempFilePaths' CREATE TABLE #tempFileInformation (FilePath VARCHAR(500), FileSize VARCHAR(100)) IF @@error <> 0 SELECT @lResultString = '1.a Unable to create #tempFileInformation' CREATE TABLE #FinalOutput (FullPathAndFile varchar(400), NameOfFile VARCHAR(400), SizeInMB DECIMAL(13,2), SizeInKB DECIMAL(13,2)) IF @@error <> 0 SELECT @lResultString = '1.a Unable to create #FinalOutput' --get the list of data files SELECT @lComm = 'dir "' + @i_DataFileLocation + '*.data*" /b /s' INSERT #DataFileList EXEC master..xp_cmdshell @lComm --Clean up the list DELETE FROM #DataFileList WHERE DataFileName NOT LIKE '%.agg%' IF @lPrintIt = 1 SELECT * FROM #DataFileList --add an identity seed for remaining rows to use in WHILE loop ALTER TABLE #DataFileList ADD RowNum int Identity(1,1) --loop through DataFileName values and get file size -- from http://stackoverflow.com/questions/7952406/get-each-file-size-inside-a-folder-using-sql SET @lcnt = (select count(*) from #DataFileList) WHILE @lcnt <> 0 BEGIN BEGIN DECLARE @filesize INT SET @CurrentDirectory = (SELECT DataFileName FROM #DataFileList WHERE RowNum = @lcnt) SET @lcomm = 'dir "' + @CurrentDirectory +'"' ------------------------------------------------------------------------------------------ -- Clear the table DELETE FROM #tempFilePaths INSERT INTO #tempFilePaths EXEC MASTER..XP_CMDSHELL @lcomm --delete all directories DELETE #tempFilePaths WHERE Files LIKE '%<dir>%' --delete all informational messages DELETE #tempFilePaths WHERE Files LIKE ' %' --delete the null values DELETE #tempFilePaths WHERE Files IS NULL --get rid of dateinfo UPDATE #tempFilePaths SET files =RIGHT(files,(LEN(files)-20)) --get rid of leading spaces UPDATE #tempFilePaths SET files =LTRIM(files) --split data into size and filename ---------------------------------------------------------- -- Clear the table DELETE FROM #tempFileInformation; -- Store the FileName & Size INSERT INTO #tempFileInformation SELECT RIGHT(files,LEN(files) -PATINDEX('% %',files)) AS FilePath, LEFT(files,PATINDEX('% %',files)) AS FileSize FROM #tempFilePaths -------------------------------- -- Remove the commas UPDATE #tempFileInformation SET FileSize = REPLACE(FileSize, ',','') -------------------------------------------------------------- -- Store the results in the output table -------------------------------------------------------------- INSERT INTO #FinalOutput (FullPathAndFile, NameOfFile, SizeInMB, SizeInKB) SELECT @CurrentDirectory, FilePath, CAST(CAST(FileSize AS DECIMAL(13,2))/ @1MB AS DECIMAL(13,2)), CAST(CAST(FileSize AS DECIMAL(13,2))/ @1KB AS DECIMAL(13,2)) FROM #tempFileInformation -------------------------------------------------------------------------------------------- Set @lcnt = @lcnt -1 END END ALTER TABLE #FinalOutput ADD DatabaseID varchar(500) ,CubeID varchar(500) ,MeasureGroupID varchar(500) ,PartitionId varchar(500) ,AggregationID varchar(500) /* --Run the following script for trouble shooting undesired output SELECT * ,(CHARINDEX('.det\',FullPathAndFile,1)) as EndHere ,(CHARINDEX('.cub\',FullPathAndFile,1)) as StartHere ,(CHARINDEX('.prt\',FullPathAndFile,1) + 4) - (CHARINDEX('.det\',FullPathAndFile,1) + 5) ,SUBSTRING(FullPathAndFile,CHARINDEX('.det\',FullPathAndFile,1) + 5,25) ,SUBSTRING(FullPathAndFile,CHARINDEX('.det\',FullPathAndFile,1) + 5,(CHARINDEX('.prt\',FullPathAndFile,1) + 4) - (CHARINDEX('.det\',FullPathAndFile,1) + 5)) FROM #FinalOutput */ UPDATE #FinalOutput SET DatabaseID = SUBSTRING(FullPathAndFile,LEN(@i_DataFileLocation) + 1,CHARINDEX('.db\',FullPathAndFile,1) - LEN(@i_DataFileLocation) + 2) ,CubeID = SUBSTRING(FullPathAndFile,CHARINDEX('.db\',FullPathAndFile,1) + 4,CHARINDEX('.cub\',FullPathAndFile,1) - CHARINDEX('.db\',FullPathAndFile,1)) ,MeasureGroupID = SUBSTRING(FullPathAndFile,CHARINDEX('.cub\',FullPathAndFile,1) + 5,CHARINDEX('.det\',FullPathAndFile,1) - CHARINDEX('cub\',FullPathAndFile,1)) ,PartitionID = SUBSTRING(FullPathAndFile,CHARINDEX('.det\',FullPathAndFile,1) + 5,(CHARINDEX('.prt\',FullPathAndFile,1) + 4) - (CHARINDEX('.det\',FullPathAndFile,1) + 5)) ,AggregationID = SUBSTRING(FullPathAndFile,CHARINDEX('.prt\',FullPathAndFile,1) + 5,250) IF @lPrintIt = 1 SELECT * FROM #FinalOutput WHERE DatabaseID like @i_DatabaseId --get total partition sizes on disc select DatabaseID ,CubeID ,MeasureGroupID ,PartitionID ,SumOfAggSizeInKB = SUM(SizeInKB) ,SumOfAggSizeInMB = SUM(SizeInMB) ,SumOfAggSizeInGB = SUM(SizeInMB) / 1000 FROM #FinalOutput WHERE DatabaseID like @i_DatabaseId AND CubeID like @i_CubeId GROUP BY DatabaseID, CubeID, MeasureGroupID, PartitionID ORDER BY DatabaseID, CubeID, MeasureGroupID, PartitionID return I received this little tip from a colleague and thought I'd pass it on hoping to be of help to someone else. Problem: Dynamic time calculations in multidimensional cubes are not by nature formatted. It would be nice to at least return percent time calculations as percentages. Problem Illustrated: In the screen print below, [Prior Period % Change], [YTD % Change] ... columns are presented in a pivot table by default without a percentage sign. 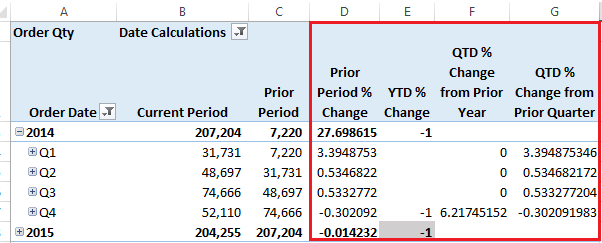 Desired Result: Automatically format percentage calculations appearing in a pivot table with a percentage sign. Assumption: You are familiar with creating MDX time calculations that can be applied against any measure in a multidimensional cube. Solution: Scope for your percentage time calcs at the end of your MDX script, and format them as a percent. --format percentages SCOPE( {[Date Calculations].[Date Calculation Name].[Prior Period % Change], [Date Calculations].[Date Calculation Name].[YTD % Change], [Date Calculations].[Date Calculation Name].[QTD % Change from Prior Year], [Date Calculations].[Date Calculation Name].[QTD % Change from Prior Quarter], [Date Calculations].[Date Calculation Name].[MTD % Change from Prior Year], [Date Calculations].[Date Calculation Name].[MTD % Change from Prior Month], [Date Calculations].[Date Calculation Name].[WTD % Change from Prior Year], [Date Calculations].[Date Calculation Name].[WTD % Change from Prior Week]} ); THIS = ([Measures].currentmember); FORMAT_STRING(this)="Percent"; END SCOPE; Result Illustrated: Without having to format the percentage calculation columns or rows in Excel, they will come in formatted when selected from PivotTable Fields. 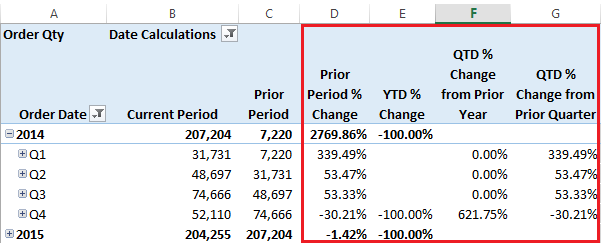 Important Note!! This only works with NEW pivot tables. If your pivot table or chart has already been created, doing a <Data Ribbon --> Refresh> in Excel will not update the formatting. You'll see your new MDX work when you <Insert> new.
Detail MDX Script Illustrated: SCOPE ([Date Default].[Y-Q-M-D Hier].MEMBERS); --YEAR CALCULATIONS --Year To Date [Date Calculations].[Date Calculation Name].[YTD] = AGGREGATE ( {[Date Calculations].[Date Calculation Name].[Current Period]} * PERIODSTODATE ( [Date Default].[Y-Q-M-D Hier].[Year], [Date Default].[Y-Q-M-D Hier].CURRENTMEMBER ) ); --Year to Date Prior Year [Date Calculations].[Date Calculation Name].[YTD Prior Year] = AGGREGATE ( {[Date Calculations].[Date Calculation Name].[Current Period]} * PERIODSTODATE ( [Date Default].[Y-Q-M-D Hier].[Year], PARALLELPERIOD ( [Date Default].[Y-Q-M-D Hier].[Year], 1, [Date Default].[Y-Q-M-D Hier].CURRENTMEMBER ) ) ); END SCOPE; --PRIOR PERIOD & YEAR --Prior Period [Date Calculations].[Date Calculation Name].[Prior Period]= AGGREGATE ([Date Default].[Y-Q-M-D Hier].CurrentMember.PrevMember, [Date Calculations].[Date Calculation Name].[Current Period]); --calculate change [Date Calculations].[Date Calculation Name].[Prior Period Change] = [Date Calculations].[Current Period] - [Date Calculations].[Prior Period]; [Date Calculations].[Date Calculation Name].[YTD Change] = [Date Calculations].[YTD] - [Date Calculations].[YTD Prior Year]; --calculate % change [Date Calculations].[Date Calculation Name].[Prior Period % Change] = DIVIDE (([Date Calculations].[Date Calculation Name].[Current Period] - [Date Calculations].[Date Calculation Name].[Prior Period]), [Date Calculations].[Date Calculation Name].[Prior Period],0); [Date Calculations].[Date Calculation Name].[YTD % Change] = DIVIDE (([Date Calculations].[Date Calculation Name].[YTD] - [Date Calculations].[Date Calculation Name].[YTD Prior Year]), [Date Calculations].[Date Calculation Name].[YTD Prior Year],0); --format percentages SCOPE( {[Date Calculations].[Date Calculation Name].[Prior Period % Change], [Date Calculations].[Date Calculation Name].[YTD % Change]} ); THIS = ([Measures].currentmember); FORMAT_STRING(this)="Percent"; END SCOPE; How to extract a list of attributes from a SSAS multidimensional cube without using a measure12/2/2015 Often consumers of a SSAS multidimensional cube will want a list of attributes from the cube without having to select a measure. Recently, users I've been working with have wanted to do three things:
Assumption: The reader of this post knows how to create a data connection in Excel to a SSAS MultiD cube, and is familiar with creating datasets in SSRS. Get a List of Attributes in an Excel Pivot Table: Be default, Excel will display a list of attributes when no measure is selected. Simply create a new pivot table and place an attribute on Rows leaving Filters, Columns and Values empty. 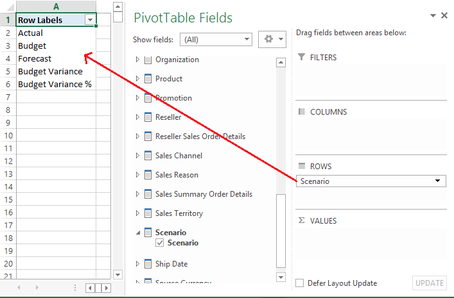 Depending on your cube design, you may need to change the properties of the pivot table to Show items with no data on rows. (You wouldn't think this should make a difference when there is no measure selected for the pivot, but it does.) 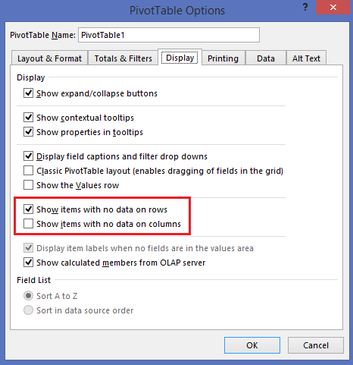 Get a List of Attributes in PowerPivot for Excel: The tiny trick here is to know about the Show Empty Cells button found in the Table Import Wizard screen. Without the Show Empty Cells button clicked, you will receive a No rows found. Click to execute the query message. 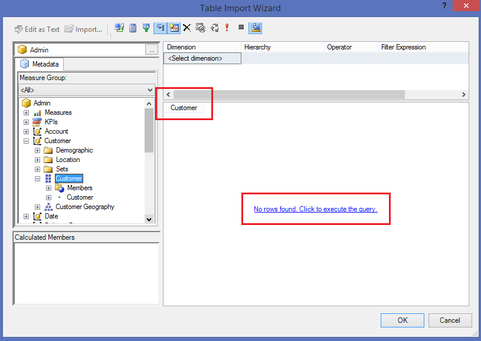 Click the Show Empty Cells button, and you will get a list of dimension attribute values without a measure. 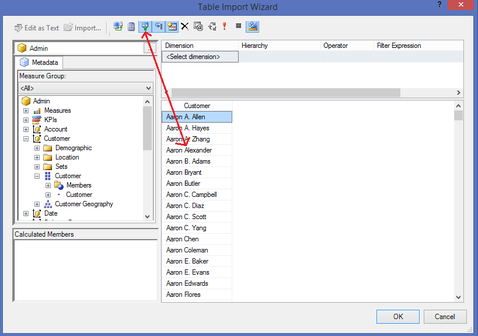 The result is a list of dimension attribute(s) in a PowerPivot table with no measure needed. 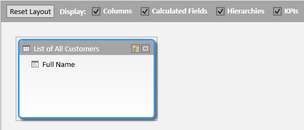 Get a List of Attributes in SSRS Acquiring a list of attribute values in SSRS is a bit more challenging because you need a bit of MDX, but never fear -- take my MDX given below and make it your own. First, I strongly recommend the use of Shared Datasets in SSRS when selecting data in SSRS that could be used by more than one report. Data sources for drop down pick lists are excellent reasons to create a shared dataset: a list of relative dates, codes, descriptions, doctor names, procedures, products etc. In SSRS Query Designer, copy and paste the following MDX, or your variation thereof. SELECT {} on 0, [Date].[Calendar].[Date].Members ON 1 FROM [Adventure Works] 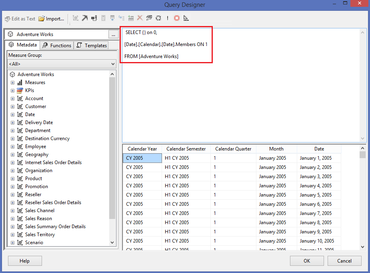 WITH MEMBER [Measures].[Level Name] as [Date].[Calendar].CurrentMember.Level.Name MEMBER [Measures].[Ordinal No] as [Date].[Calendar].CurrentMember.Level.Ordinal SELECT {[Measures].[Level Name], [Measures].[Ordinal No]} on Columns ,NON EMPTY [Date].[Calendar].members on Rows FROM [Adventure Works] 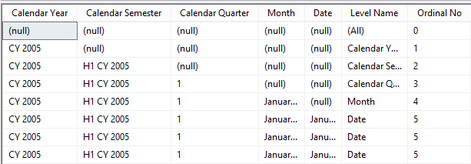 SELECT { } on 0, [Customer].[Education].Children on 1 FROM [Adventure Works] 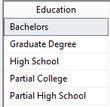 The following MDX uses a [Date Filters] table created specifically for SSRS parameters. Like [Date Calculations], it has no relationship to any measure group in the cube. The t-SQL in the cube DSV looks like this --> SELECT 1 as DateFilterKey, 'CurrentDateTime' as DateFilterName, Convert(varchar(25),GetDate(),120) as DateFilterValue UNION SELECT 2, 'CurrentDate' as DateCalculationName, Convert(varchar(25),Convert(Date,GetDate()),110) UNION SELECT 3, 'CurrentDayNo', Convert(varchar(2),Day(GetDate())) UNION SELECT 4, 'CurrentWeekNo', Convert(varchar(2),DatePart(Week, GetDate())) UNION SELECT 5, 'CurrentMonthNo', Convert(varchar(2),Month(GetDate())) UNION SELECT 6, 'CurrentYearMonthNo', Convert(char(6),Convert(int,Convert(char(4),Year(GetDate())) + RIGHT(RTrim('00' + Convert(char(2),Month(GetDate()))),2))) UNION SELECT 7, 'PriorDay1', Convert(varchar(25),Convert(DateTime,Convert(varchar(8),GetDate() -1,112),1),110) UNION SELECT 8, 'PriorWeekNo', Convert(varchar(2),DatePart(Week, GetDate() - 7)) UNION SELECT 9, 'PriorMonthNo', Convert(varchar(2),DatePart(mm,dateadd(day,(day(GetDate())-1)*-1,dateadd(month,-1,GetDate())))) UNION SELECT 10, 'SameDayLastYear', Convert(varchar(25), CASE WHEN Right(Convert(char(8),GetDate(),112),4) = '0229' THEN GetDate() - 366 ELSE GetDate() - 365 END,110) UNION SELECT 11, 'None', '01-01-2054' Find a more extensive list of t-SQL data calculations here --> http://www.delorabradish.com/dba/t-sql-date-calculations. The MDX in SSRS' Query Designer is this --> //get all values returned in string format SELECT {} on 0, ([Date Filters].[Date Filter Name].Children, [Date Filters].[Date Filter Value].Children) ON 1 FROM [Time Calc POC] 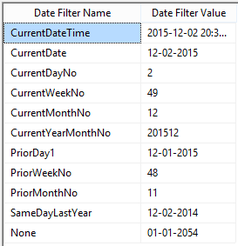 If you just want date data types for your pick list and you have used naming conventions in your [Date Filter Name] attribute, your MDX would be as follows: //get filter values that are of a date data type only SELECT {} on 0, { FILTER([Date Filters].[Date Filter Name].Children, Right([Date Filters].[Date Filter Name].CurrentMember.Name,2) <> 'No' ) * [Date Filters].[Date Filter Value].Children } ON 1 FROM [Time Calc POC] 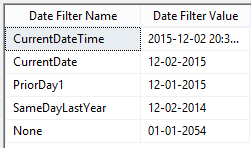 Get a list of attribute values from a hierarchy. SELECT {} on 0, [Product].[Product Categories].[Product].Members on 1 FROM [Adventure Works] 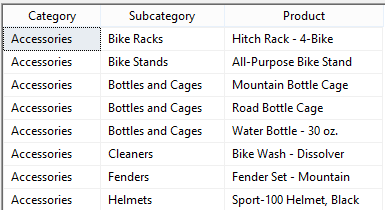 Get a list of attributes including the SSRS parameter value. WITH MEMBER [Measures].[ParameterCaption] AS [Promotion].[Promotion Category].CURRENTMEMBER.MEMBER_CAPTION MEMBER [Measures].[ParameterValue] AS [Promotion].[Promotion Category].CURRENTMEMBER.UNIQUENAME SELECT {[Measures].[ParameterCaption], [Measures].[ParameterValue]} ON COLUMNS , [Promotion].[Promotion Category].Children on ROWS FROM [Adventure Works]  Include the All member WITH MEMBER [Measures].[ParameterCaption] AS [Promotion].[Promotion Category].CURRENTMEMBER.MEMBER_CAPTION MEMBER [Measures].[ParameterValue] AS [Promotion].[Promotion Category].CURRENTMEMBER.UNIQUENAME SET [Promotion Category] AS [Promotion].[Promotion Category].ALLMEMBERS SELECT {[Measures].[ParameterCaption], [Measures].[ParameterValue]} ON COLUMNS , [Promotion Category] on ROWS FROM [Adventure Works] 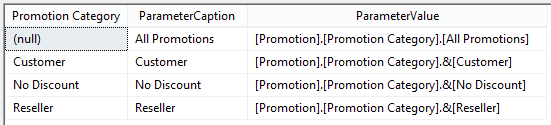 I hope this little blog post helps to get you started on extracting attribute values without using a related measure. Enjoy!
Issue: When you open a dimension (*.dim) file in a Visual Studio 2012 project, you either receive the following error, the dimension opens with a blank data source view (DSV) pane, or the dimension opens with no DSV pane at all. This is highly problematic when you need to add new attributes to the dimension. COM Error Example. Click <OK> and the dimension will open with either no DSV pane, or an empty DSV pane.  Empty DSV pane example: 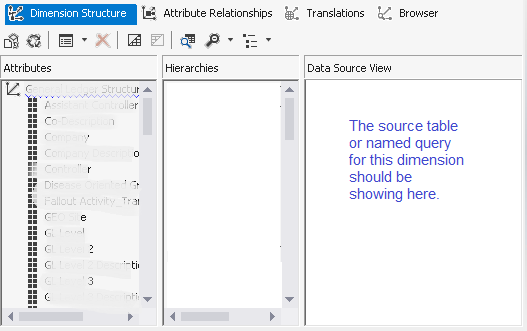 Internet Solution: You may have already read elsewhere on the Internet that this issue can be caused by the developer’s Control Panel --> Clock, Language & Region --> Language not being set to English (United States) and/or Control Panel --> Clock, Language & Region --> Region --> Home Location not being set to United States. As this behavior only manifested itself for us in two of twenty dimensions and our Language and Regions were already set to United States, we pursued other alternatives. There are two relatively simple fixes, providing your dimension sources from a single table. Alternative Solution #1 (preferred):
As show here --> 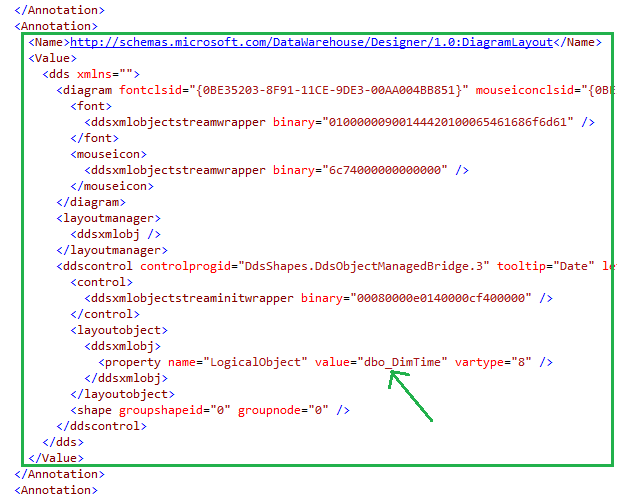 4. Now open the XML for the offending dimension and find the same section.
5. Copy and paste the XML from the working dimension. 6. Update the LogicalObject property which should contain the table name or named query used by the offending dimension. 7. Save the dimension file to disc, then reopen it in Solution Explorer as usual. Your DSV pane should now contain the solution DSV object you specified in LogicalObject. Alternative Solution #2 We also found a workable solution to be right mouse clicking in the empty dimension's DSV pane and selecting Show All Tables. This is not the preferred solution because if you have many tables in your solution’s DSV, you have to wade through them all to find the one table you want for your dimension. This solution also did not work when the Error HRESULT E_FAIL has been returned from a call to a COM component error resulted in no DSV pane at all. Side Note: If this error is happening when you try to open the solution’s DSV, it can be caused by the DSV having been created in Visual Studio 2014 while the developer is trying to open the DSV in Visual Studio 2012. (You can read a very good MSDN blog post on how to fix this particular issue here --> http://blogs.msdn.com/b/sqlblog/archive/2015/06/10/ssas-dsv-com-error-that-breaks-ssdt-ssas-design-backward-compatibility.aspx.) Having come from an OLTP background, I used to think that ignoring duplicate keys in a dimension resulted in duplicated fact records (measures) in a multidimensional cube. This, however, is not the case. Even if the primary key of the dimension is duplicated, SSAS is smart enough to not duplicate related fact rows. The POC explained in this blog post was originally created to prove the very opposite, but now I have learned a different version of the truth, and I thought this little POC might interest someone else. So, let’s get started: First, just because we can get away with something, is not a good reason to do it. In other words, even though SSAS lets us have duplicate primary dimension keys, and what SSAS considers duplicate values in columns, is not an excuse to allow them. Data integrity should be considered non-negotiable. Second, the dimension property I am talking about can be found in any dimension under [Dimension Name] --> Properties --> ErrorConfiguration --> KeyDuplicate.  99.9% of the time, the correct selection for the KeyDuplicate property is ReportAndStop. I strongly suggest that each of us just decide to set it now and work through the data cleansing issues that this error handling will almost assuredly expose. Specifically, the error that SSAS generates is as follows: Dimension Processing Error: Errors in the OLAP storage engine: A duplicate attribute key has been found when processing: Table: 'Dimension Name', Column: 'Column Name', Value: 'abc123’. The attribute is 'Attribute Name'. Third, let us be clear, “duplicate key” does not just mean “duplicate primary key”. What Analysis Services is talking about is the KeyColumns property associated with each attribute within a dimension. In the screen print below, the key of the Product attribute is the ProductKey column from the Product table. This happens to also be the primary key of both the table and the dimension. 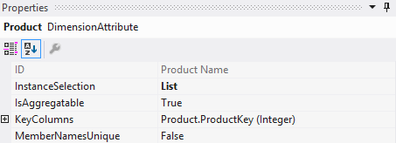 However, every attribute in a dimension has a KeyColumns property and for most attributes, the KeyColumns value is the column itself. If the attribute is used in a hierarchy, you will often find that the KeyColumns property is a composite key containing greater than one column from the source table. In the screen print below, the key of the Calendar Quarter attribute is the composite column values of CalendarYear and CalendarQuarter columns from the Date table. 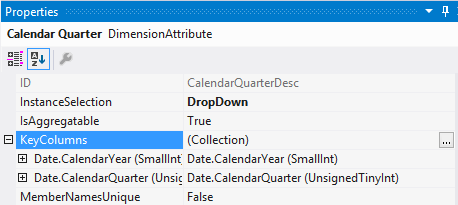 Now, let’s mock up a little data and see what really happens if we set the ErrorConfiguration:KeyDuplicate property to IgnoreError instead of ReportAndStop. The DSV tables I created are pictured here: 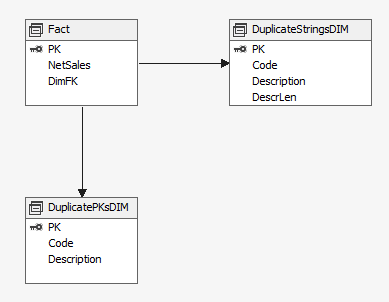 For the Fact table…. SELECT 1 AS PK, 100 AS NetSales, 1 AS DimFK UNION SELECT 2 AS PK, 999 AS NetSales, 2 AS DimFK For the DuplicateStringsDIM … SELECT 1 AS PK, 'CODE 1' AS Code, 'Descr 1' AS Description, LEN('Descr 1') AS DescrLen UNION SELECT 2 AS PK, 'Code 1' AS Expr1, 'Descr 1' + CHAR(9) AS Expr2, LEN('Descr 1' + CHAR(9)) UNION SELECT 3 AS PK, 'Code 3' AS Expr1, 'Descr 3' AS Expr2, LEN('Descr 3') For the DuplicatePKsDIM…. SELECT 1 AS PK, 'Code 1' AS Code, 'Descr 1' AS Description UNION SELECT 1 AS PK, 'Code 2' AS Expr1, 'Descr 2' AS Expr2 UNION SELECT 2 AS PK, 'Code 3' AS Expr1, 'Descr 3' AS Expr2 I then created two dimensions – nothing fancy, just regular old dimensions with no hierarchies. 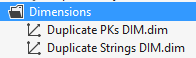 Each dimension has ErrorConfiguration:KeyDuplicate set to IgnoreError.  Next, I built a simple cube, and processed the cube. 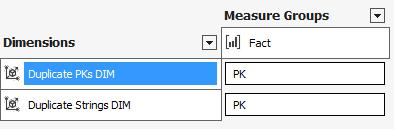 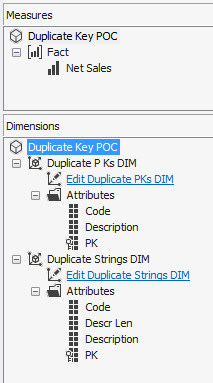 While the cube was taking 5 seconds to process full, I jumped over to SSMS (SQL Server Management Studio) and wrote a little t-SQL. --Create the table to hold duplicate code values insert @DuplicateStringsDIM SELECT * FROM ( SELECT 1 AS PK, 'Code 1' AS Code, 'Descr 1' AS Description UNION SELECT 2 AS PK, 'CODE 1' AS Expr1, 'Descr 1' + CHAR(9) AS Expr2 UNION SELECT 3 AS PK, 'Code 3' AS Expr1, 'Descr 3' AS Expr2 ) x --Create the table to hold duplicate primary key values DECLARE @DuplicatePKsDIM TABLE (dPK int, Code varchar(30), Descr varchar(60)) insert @DuplicatePKsDIM SELECT * FROM ( SELECT 1 AS PK, 'Code 1' AS Code, 'Descr 1' AS Description UNION SELECT 1 AS PK, 'Code 2' AS Expr1, 'Descr 2' AS Expr2 UNION SELECT 2 AS PK, 'Code 3' AS Expr1, 'Descr 3' AS Expr2 ) x --create the table to hold the measures DECLARE @FactTbl TABLE (fPK int, NetSales int, DimFK int) insert @FactTbl SELECT * FROM ( SELECT 1 AS PK, 100 AS NetSales, 1 AS DimFK UNION SELECT 2 AS PK, 999 AS NetSales, 2 AS DimFK ) x --the results are as expected --the fact record is duplicated for each duplicate DIM PK SELECT * from @FactTbl f LEFT JOIN @DuplicatePKsDIM d1 on f.DimFK = d1.dPK 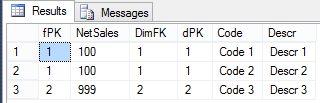 --the results are as expected: --the 2nd 'Descr 1' value has a special character, and therefore groups into two separate rows SELECT d2.Descr, SUM(NetSales) as SumOfNetSales from @FactTbl f LEFT JOIN @DuplicateStringsDIM d2 on f.DimFK = d2.dPK GROUP BY d2.Descr 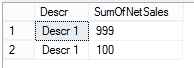 The above results in t-SQL makes sense
Now let’s browse the cube whose data source view contained the exact same rows. First, test the measure all by itself. All is well. 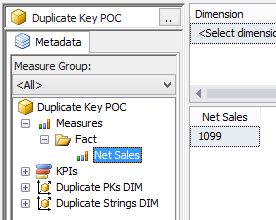 Now look what happens when we slice by PK. 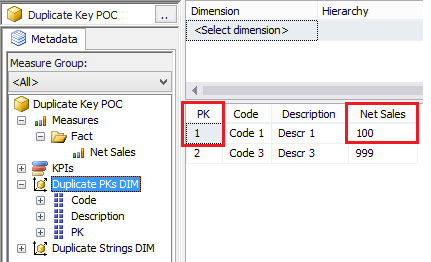 The reality is that there are two PKs with a value of #1 in the DSV, but SSAS has not duplicated the measure amount. We still have just 100 net sales for dimension PK #1. Furthermore, we have lost ‘Code 2’ and ‘Descr 2’, why? Analysis services has taken the row values of the first instance of the PK, and has ignored the second. This phenomena has nothing to do with the measure group. The following MDX query shows what is actually in the [Duplicate PKs DIM] -- two rows and not three. 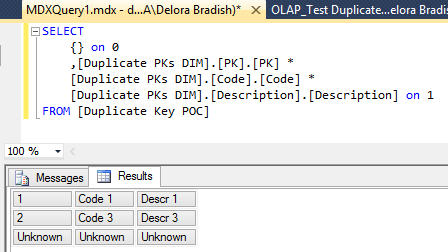 Don’t forget what was really in our data source table, @DuplicatePKsDim: 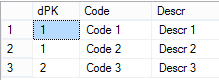 Now let’s look at what SSAS considers a “duplicate” in the [DuplicateStringsDIM] dimension. 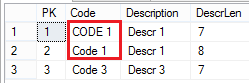 If ErrorConfiguration:KeyDuplicate is set to ReportAndStop...
attribute.
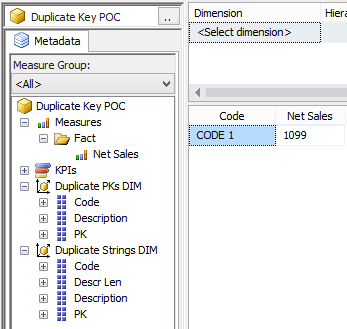 In summary,
Issue: When working in Excel 2013 Prof Ed and a SQL Server 2012 multidimensional cube, you receive the following error when adding a hierarchy or attribute to the FILTERS section of the PivotTable Fields GUI. 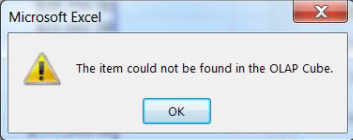 The above error is usually caused by an object that was removed or renamed in the cube. However, this was not the case for a recent client. I Googled the error (like you probably did to even arrive at my blog site), but found nothing except that an object was deleted or removed from the cube. As this was not our scenario, I'm doing this little write-up hoping that is will be helpful to someone in the same predicament.
Summary Solution:
Cause of the Error: Unknown. I have found on more than on one occasion that the underlying XML of multidimensional cubes becomes "out of sync". I realize this isn't a very technical response, but if you have spent time comparing "working" XML code to "unworking" code, you know that sometimes it is easier to just remove and readd the object. Resolution Logic: In the latest occurrence of this error, I worked through the following steps trying to find the cause before throwing in the towel and removing the dimension from the cube. It was determined that ..
It was a bit of work to remove a shared dimension from a large cube and re-add it, checking to make sure all cube relationships and properties remained the same, but in the end, this is what fixed the error. if you have come across this same problem and have found a better solution, please post it in blog comments. I'd like to hear your creative solution! Sometimes users do not want to see time calculations for days in the future -- even if there is data. To “nullify” date calculation for days in the future, follow these steps: 1. Create an IsFutureDate named calculation in your date dimension. CASE WHEN FullDateAlternateKey > GetDate() THEN 1 ELSE 0 END 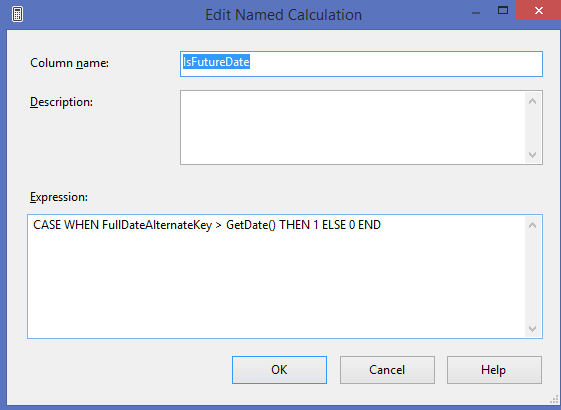 2. Add the new attribute to your date dimension. 3. Add the following script to the end of your MDX time calculations. --set future date calculations to NULL SCOPE ([Date Default].[Is Future Date].&[1], [Date Ship].[Is Future Date].&[1], [Date Due].[Is Future Date].&[1]); [Date Calculations].[Date Calculation Name].[YTD] = NULL; [Date Calculations].[Date Calculation Name].[YTD Change] = NULL; [Date Calculations].[Date Calculation Name].[YTD % Change] = NULL; [Date Calculations].[Date Calculation Name].[YTD Prior Year] = NULL; [Date Calculations].[Date Calculation Name].[MTD] = NULL; //add additional time calculations here as needed END SCOPE; 4. Verify the results. In the screen print below, the current date was 7/24/2015. All future days returned empty cell values. 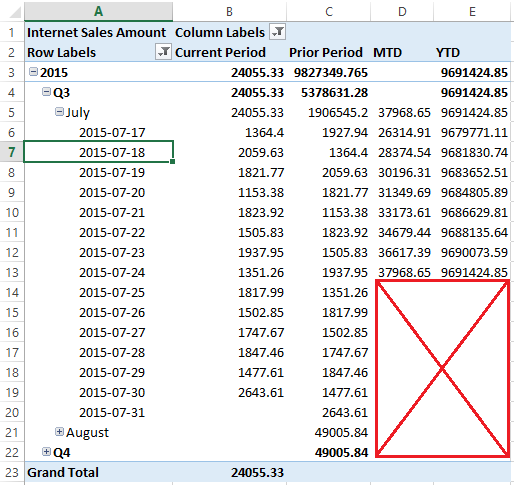 |
|||||||||||||
| Microsoft Data & AI | SQL Server Analysis Services |

 RSS Feed
RSS Feed
