Azure Data Factory (ADFv1) JSON Example for Salesforce Initial Load RelationalSource Pipeline4/25/2017 This blog post is intended for developers who are new to Azure Data Factory (ADF) and just want a working JSON example. In another blog post here, I've given you the 10K foot view of how data flows through ADF from a developer's perspective. This blog post assumes you understand ADF data flows and are now simply wish for a JSON example of a full initial data load into [somewhere]. The JSON provided here pulls data from Salesforce and creates output files in an Azure Data Lake. Prerequisites: 1. An established Azure subscription 2. An Azure Data Factory resource 3. An Azure Data Lake resource 4. An Azure Active Directory Application that has been given permissions in your Azure Data Lake Short Version to create AD application: AD --> App registrations --> new application registration Short Version to give ADL permissions: ADL --> Data Explorer --> click on top / root folder --> Access JSON Scripts: To extract data from Salesforce using ADF, we first need to create in ADF a linked service for Salesforce. { "name": "SalesforceDataConnection", "properties": { "type": "Salesforce", "typeProperties": { "username": "[email protected]", "password": "MyPassword", "securityToken": "MySecurityTokenObtainedFromSalesforceUI", "environmentUrl": "test.salesforce.com" } }, } Note: If you are pulling from an actual Salesforce data store, not test, your "environmentUrl" will be "login.salesforce.com". We next need a linked service for Azure Data Lake. AAD = Azure Active Directory ADL = Azure Data Lake { "name": "ADLakeConnection", "properties": { "type": "AzureDataLakeStore", "typeProperties": { "dataLakeStoreUri": "https://MyDataLake.azuredatalakestore.net", "servicePrincipalId": "MyAAD-ApplicationID-ServicePrincipalId-ClientId-WhichAreAllTheSameThing", "servicePrincipalKey": "MyAAD-ApplicationID-key", "tenant": "MyAAD-DirectoryID", "subscriptionId": "MyADL-SubscriptionId", "resourceGroupName": "MyADL-ResourceGroup" } }, } The ADF copy wizard will generate this JSON for you, but you still need to know your IDs, so let's talk about where we find all of this. Assuming that you are currently logged in successfully to the Azure Portal ... 1 "datalakeStoreUri": Your Azure Data Lake --> Overview --> URL 2 "servicePrincipalId": Your Azure Active Directory Application --> App registrations --> YourApplicationName --> (click on the application name to see properties) --> ApplicationID 3 "servicePrincipalKey": You must have recorded this when you created the Azure Active Directory application! 4 "tenant": Your Azure Active Directory Application --> Properties --> Directory ID 5 "subscriptionId": Your Azure Data Lake --> Overview --> Subscription ID 6 "resourceGroupName": Your Azure Data Lake --> Overview --> Resource group Here are a couple of screen prints to help you out. from Azure Data Lake  from Azure Active Directory --> App registrations 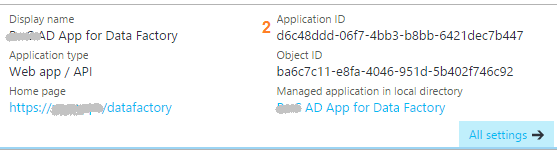 from Azure Active Directory --> Properties 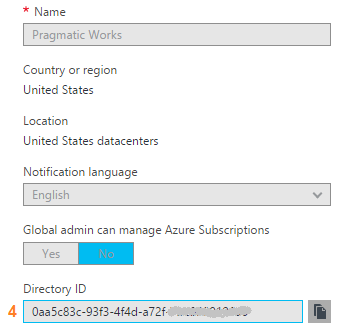 Note: your Azure Active Directory (AAD) service principal key aka Application ID (in ADF) aka Client ID (in SSIS), must be recorded at the time the Azure Active Directory application is created. There is a pop-up message in AAD which clearly reads, "Copy the key value. You won't be able to retrieve after you leave this blade." Okay, did we survive the creation of an Azure Data Lake linked service? If so, let's move on to creating an ADF input dataset for Salesforce. This JSON uses the Salesforce Account table as an example. { "name": "InputDataset-Account", "properties": { "structure": [ { "name": "Id", "type": "String" }, { "name": "IsDeleted", "type": "Boolean" }, { "name": "MasterRecordId", "type": "String" }, { "name": "Name", "type": "String" }, { "name": "Type", "type": "String" }, <a plethora of more Account columns here. remove this line from your JSON script> { "name": "Is_Processed_by_DP__c", "type": "Boolean" } ], "published": false, "type": "RelationalTable", "linkedServiceName": "SalesforceDataConnection", "typeProperties": { "tableName": "Account" }, "availability": { "frequency": "Day", "interval": 1 }, "external": true, "policy": {} }, } You will need one input (and output) dataset for EVERY Salesforce table. Furthermore, pipelines cannot share datasets, so if you want both an initial and incremental load pipeline, you will need TWO input datasets for every Salesforce table. Personally, I feel this is an ADF travesty, but once I understood pipelines and SliceStart and SliceEnd times, it is understandable howbeit a terrific pain! Okay here is a work-around tip for you: 1. Use a Visual Studio Azure Data Factory solution for source code control. 2. In the VS solution have one JSON script for initial load. Have a second JSON script for incremental load 3. In ADF, delete one pipeline before trying to create the other; in effect, you are toggling between the two JSON scripts using VS as your source code of reference. Moving on, we now need an ADF output dataset. { "name": "OutputDataset-Account", "properties": { "structure": [ { "name": "Id", "type": "String" }, { "name": "IsDeleted", "type": "Boolean" }, { "name": "MasterRecordId", "type": "String" }, { "name": "Name", "type": "String" }, { "name": "Type", "type": "String" }, <a plethora of more Account columns here. Remove this line from your JSON script> { "name": "Is_Processed_by_DP__c", "type": "Boolean" } ], "published": false, "type": "AzureDataLakeStore", "linkedServiceName": "ADLakeConnection", "typeProperties": { "fileName": "Account {Year}{Month}{Day} {Hour}{Minute}.avro", "folderPath": "Salesforce/{Year}{Month}{Day}", "format": { "type": "AvroFormat" }, "partitionedBy": [ { "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } }, { "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } }, { "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } }, { "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "hh" } }, { "name": "Minute", "value": { "type": "DateTime", "date": "SliceStart", "format": "mm" } } ] }, "availability": { "frequency": "Day", "interval": 1 }, "external": false, "policy": {} }, } Why an AVRO data type? At the writing of this blog post the SSIS Azure Feature Pack contains an Azure Data Lake Source component, but Microsoft forgot to include a text qualifier property. Oops! No one is perfect. Why partitions? This is how ADF creates time slices. In this example, I wanted my Salesforce Account ADL files to sort into nice little MyADL\Salesforce\YYYYMMDD\Account YYYYMMDD HHMM.avro buckets. Now for the grand finale, let's create an ADF pipeline. We are almost home! { "name": "InboundPipeline-SalesforceInitialLoad", "properties": { "activities": [ { "type": "Copy", "typeProperties": { "source": { "type": "RelationalSource", "query": "select * from Account" }, "sink": { "type": "AzureDataLakeStoreSink", "writeBatchSize": 0, "writeBatchTimeout": "00:00:00" } }, "inputs": [ { "name": "InputDataset-Account" } ], "outputs": [ { "name": "OutputDataset-Account" } ], "policy": { "timeout": "1.00:00:00", "concurrency": 1, "executionPriorityOrder": "NewestFirst", "style": "StartOfInterval", "retry": 3, "longRetry": 0, "longRetryInterval": "00:00:00" }, "scheduler": { "frequency": "Day", "interval": 1 }, "name": "Activity-Account" }, <Including Salesforce Opportunity here for your amazement or amusement. Remove this line from your JSON script> { "type": "Copy", "typeProperties": { "source": { "type": "RelationalSource", "query": "select * from Opportunity" }, "sink": { "type": "AzureDataLakeStoreSink", "writeBatchSize": 0, "writeBatchTimeout": "00:00:00" } }, "inputs": [ { "name": "InputDataset-Opportunity" } ], "outputs": [ { "name": "OutputDataset-Opportunity" } ], "policy": { "timeout": "1.00:00:00", "concurrency": 1, "executionPriorityOrder": "NewestFirst", "style": "StartOfInterval", "retry": 3, "longRetry": 0, "longRetryInterval": "00:00:00" }, "scheduler": { "frequency": "Day", "interval": 1 }, "name": "Activity-Opportunity" } ], "start": "2017-04-17T19:48:55.667Z", "end": "2099-12-31T05:00:00Z", "isPaused": false, "pipelineMode": "Scheduled" }, } Getting your new JSON scripts to execute on demand is another blog post. Hint: Your "start" UTC time of your pipeline controls this! Download all JSON scripts below. Enjoy!
0 Comments
Leave a Reply. |
|||||||||||||||
 RSS Feed
RSS Feed
