|
I was asked recently to draw out a visual for Azure Data Factory control flow between source and final Azure Data Lake destination. There are diagrams given in Microsoft's Introduction to Azure Data Factory Service, but I needed to personalize it to tell a customer's individual story. This is the short version of how I see view Azure Data Factory control flow: 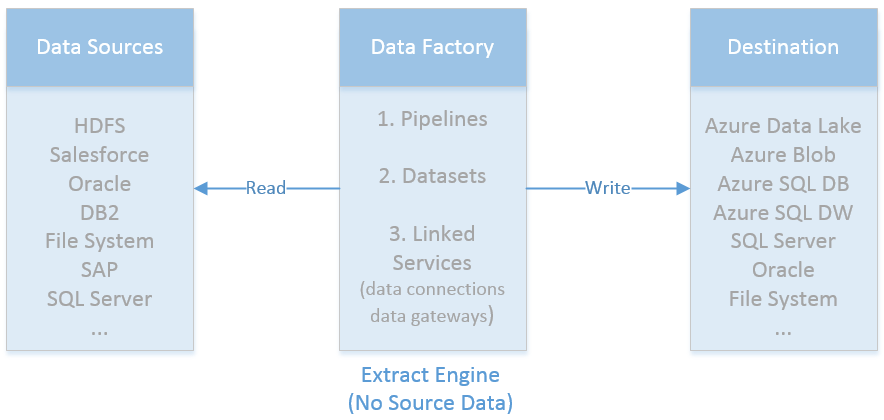 The longer version of ADF control flow still isn't that complex. However, coming from SQL Server Integration Services (SSIS), I, of course, encountered my most frustrating moments when I expected ADF to be SSIS. That never works. Informatica does not act like SSIS. Tableau is not Power BI Desktop. HP's Vertica does not function exactly like PDW or Azure DW. You get the idea. The point is, we all bring what we know to the party, but we must be willing to learn new tricks. I've started to compile "ADF Tricks" in a formatted Microsoft Word document that I affectionately refer to as my ADF Rule Book. It is basically a bunch of things I learned the hard way, but back to Azure Data Factory control flow. Let's take a deeper dive. 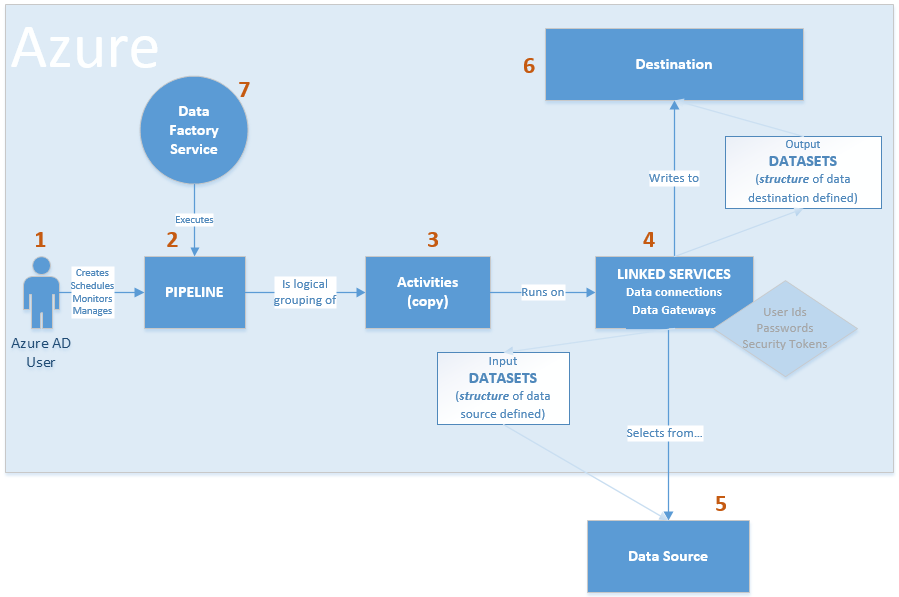 1. That is us! Welcome to the Azure Data Factory party. Our job is to create ADF objects (datasets, linked services and pipelines primarily), schedule, monitor and manage.
2. Pipelines are similar to SSIS data flows and contain one or more activities. They basically tell ADF "go pick data up from source and write it to destination. Do this every [x number of days...hours...minutes]." There are many other properties, but know this, your success or failure is determined in part by the "start" pipeline property and the "recursive" and "copyBehavior" activity properties. Read up and understand them well. 3. Activities are similar to tasks within a SSIS dataflow. Right now out-of-the-box ADF can only copy. There is no rename, move or delete capabilities on the source or destination. Another things to be clear on is that one source table or file (input dataset) must be matched up with one destination table or file, (output dataset). Each combination is a single activity, and ADF charges by activity. Input and output datasets can only be used by one pipeline. Yes, this means that for full and incremental loads, you either have to double your JSON source code (not recommended) or use source code control deleting one ADF pipeline before creating the other -- assuming they each reference the same input and output datasets. 4. Activities rely on linked services which fall into two categories: data connections and data gateways. Data connections are self-explanatory, but data gateways are how you get from the cloud to on-prem data sources. 5 & 6. You will find a list of Azure Data Factory sources and destinations here. A few tips: * The ADF Copy utility is an easy way to get source data types scripted out. I generally use a sandbox ADF for this, then copy and deploy the JSON with my own naming conventions in my development environment. * The ADF copy utility sometimes misinterprets the source and then resulting ADF datatype. It is an easy fix, but when in doubt, go for string! * ADF currently only support five file types, Text, JSON, Avro, ORC, and Parquet. Note that XML is not in the list. Avro seems the most popular. If you go with Text and are using SSIS to consume destination files from Azure Data Lake (ADL), be aware that Microsoft has forgotten to add a text qualifier property to its SSIS Azure Data Lake Store Source component which renders unusable any ADL text file that has a single end-user-entered string value. 7. The ADF service. I liken this to SQL Agent -- sort of. The "job schedule" is a property inside of the pipeline and it looks to the individual dataset last run times. Furthermore, I am not aware of way to reset a dataset last run time. This proves very challenging when during development you need to run your pipelines on demand. Tip: Keep moving back your "start" pipeline property and redeploy your pipeline. ADF looks at the "schedule" and new "start" pipeline values, checks the last run dateTime of the datasets and thinks, "Hey, those datasets haven't run for January 3rd, I'll run the pipeline now creating destination files for the new January 3rd, but also over-writing January 4th, January 5th ... to current day. " I strongly suggest that you read Azure Data Factory Scheduling Execution at least five times, then move forward to try out Microsoft Azure Scheduler.
2 Comments
Leave a Reply. |
 RSS Feed
RSS Feed
