SSIS 2016: An efficient way to handle transform and load of SCD2 (type 2 slowly changing dimensions)8/23/2017 Quick Review: This blog post is about type two slowly changing dimensions (SCD2). This is when an attribute change in row 1 results in SSIS expiring the current row and inserting a new dimension table row like this -->  SSIS comes packaged with a SCD2 task, but just because it works, does not mean that we should use it. Think of the pre-packaged Microsoft supplied SCD2 task as a suggestion. If we really want to get the job done, we will want to use Cozy Roc or Pragmatic Works Task Factory (TF). I strongly suggest Task Factory’s [Dimension Merge Slowly Changing Dimension] add-in to SSIS for the following reasons:
The key to success, in my case, was two-fold
You can read about additional performance tips from Pragmatic Works on line help (performance tab) and they have an instructional video here. The point of this blog post is to share a screen print that would have been helpful to me the first time I setup this component. 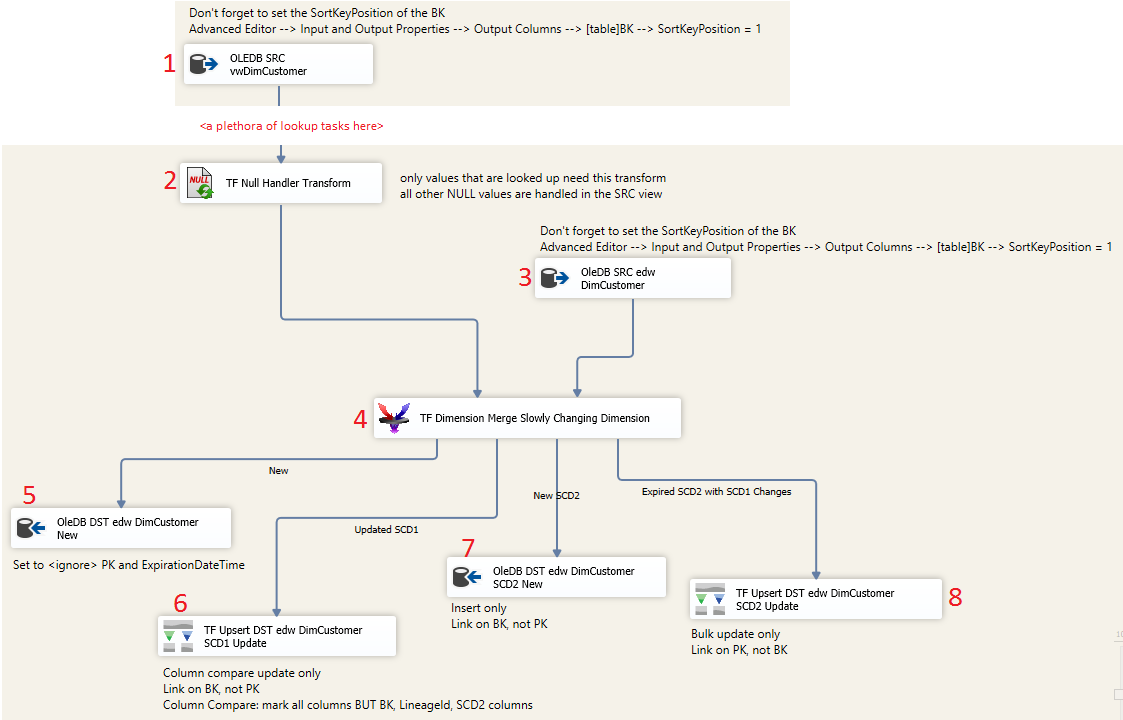 Now for the dissection...
Conclusion: Having fulling understood SCD2 concepts, this TF component took me a little bit to configure -- I had to actually think about things vs the rhythmic repetition of common data flow tasks. On first pass I skipped past the sort of the two source components and out of habit, picked up the PK in both TF Upsert components. I didn't pay attention to the <New> OleDB mapping and tried to insert my edw.DimCustomer.PK (hello?!) . My advice is to SLOW DOWN and get the first SCD2 dimension SSIS package built and aggressively tested, then fall back into the rinse and repeat rhythm of SSIS package development. If you get stuck, reach out to Pragmatic Works Product Support. I highly recommend their online chat.
0 Comments
SSIS 2016, An efficient way to mark deleted source system rows in a persisted data warehouse table8/23/2017 Even though many people think data warehouses ETLs (extract, transform and load) should contain insert data flows only, the vast majority of people I work with also have to deal with updates. Many have to also handle marking data warehouse rows as IsDeleted = "Y" in their ODS and EDW data repositories. If you are working with a dimension tables with less than 500K rows (an estimate), a traditional lookup task might work just fine. The data flow would look like this: 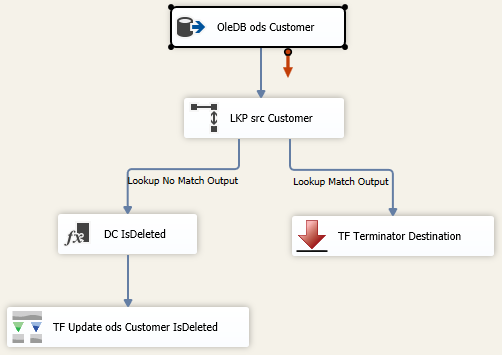 (TF = Task Factory. This is a great SSIS add-in for a nominal cost available from Pragmatic Works.) The problem with the above methodology is that although it may work, it is not efficient. I am a firm believer in performance tuning SSIS packages attempting to shave off minutes, and often seconds. Consequently, just because we get a green check mark, that is NOT indicative of “all is well”. In the above data flow, every ods.Customer has to be looked up in the src.Customer table. P-a-i-n-f-u-l! As with everything SSIS, there are multiple ways to get the same data flow accomplished, and I tip my hat to those of you who like to write C#. In my experience, C# seems to be able to complete a data flow task faster than many comparable SSIS components, but C# is not my go-to solution. An entry-level developer will probably be maintaining and enhancing the package, so I try to find an alternative. Keeping with OOP (object oriented programming) techniques, I tested two alternative options this week that I thought were worth a share.
Working with a dimension table containing 5 million rows (it was “people” and there really were that many people so there was no trimming down the dimension row count), MergeJoin took 3 minutes. The standard lookup took over 20 minutes. Assumptions:
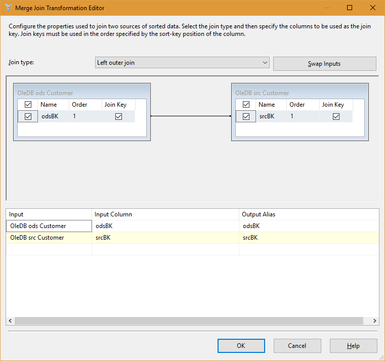
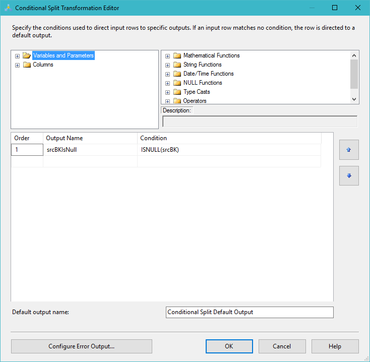
MergeJoin Solution: It isn’t that complex. Add two OleDB source tasks to a data flow: one for your actual source that is deleting records (and in my opinion, behaving badly, but sometimes that just cannot be helped) and a second source component for the data warehouse. Use a MergeJoin to bring the two together, use a conditional split to send (now) missing PKs to an upsert or stage destination. I like to use TF (Task Factory’s) Upsert component as it is super easy to configure. A MergeJoin solution for marking data warehouse records as deleted in the source will look something like this: 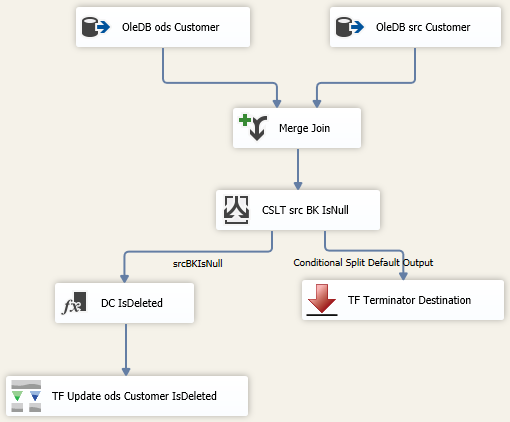 Key to performance success in the above data flow is sorting both the ods.Customer and src.Customer tables including setting the sort properties of the Advanced Editor. Right mouse click on the OleDB source task --> Show Advanced Editor --> Input and Output Properties tab --> Ole DB Source Output --> IsSorted property = True. On this same tab click on Ole DB Source Output --> Output Columns --> [Your Business Key Column Name]--> SortKeyPosition = 1 For those new to SSIS, the Merge Join and Conditional Split components are pictured below to fill in the blanks of the MergeJoin data flow.
Temp Table Solution: I won’t spend too much time here because this option was a bit slower than the MergeJoin, and requires a stage table in the same database as the ODS. The basic concept is to stage the unique BKs (business keys) of the source into your ODS database using a TRUNCATE and full reINSERT. Then perform the lookup between your ODS database and the newly loaded stage table. This does work, and avoids a lookup to a 2nd server or source, but it is not my personal preference. A temp table solution (stg.Customer) will look something like this: 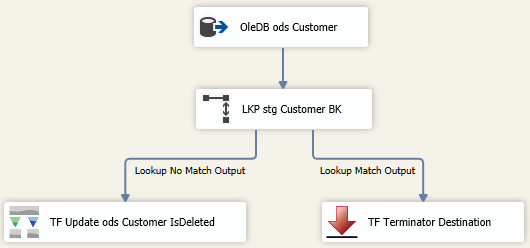 Conclusion: We might not like it, but sometimes we must make a full comparison between our incrementally loaded data warehouse table and a source system to find business keys that no longer exist in the source. SSIS is built to handle this, but we still need to try several options to find the best performing solutions for our unique environments.
This blog post just dealt with the ODS; deleted source records still have to be handled in the EDW. I loath seeing IsDeleted columns in true data warehouses. Is there a reporting requirement for deleted records? Are you going to put an index on that column? Will you have two sets of views, one with deleted records and one without? A much better way to handle deleted source records already persisted to an EDW is to create a DEL (deleted) schema and move the edw.Customer rows to del.Customer. It takes more ETL effort, but once developed, always done. ROI (return on investment) is not having to wade through deleted rows in the EDW. I feel another blog post coming ... I classify SSIS errors into two groups:
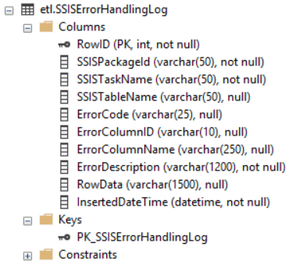
This blog post is about "Report and Pass" which I first talked about in Top 5 Best Practices for SSIS. There are hundreds of SSIS potential errors, and to start with, I STRONGLY recommend BI xPress from Pragmatic Works. SSIS package deployment and monitoring aside, however, what I'd like to talk to you about here is error handling inside of a data flow so that we are not sacrificing the permanent, the completion of your master-master package, on the alter of the immediate, a dateTime data type that came through last night in a text file's integer column space. Last month I dusted off an old SQL 2008 SSIS package written about that same time. I was hoping that error handling in SSIS through VS 2015 had some cool new task to "report and pass". Not finding anything, I was hoping that Task Factory, a second "don't deploy without it" SSIS tool, had picked up the slack. Nothing doing, as some say. Here then is a review of an old proven SSIS methodology for recording data of redirected errors in a SSIS data flow. Process Overview First we need a SQL Server data table to hold our error rows. You might consider something like this:
CONSTRAINT [PK_SSISErrorHandlingLog] PRIMARY KEY CLUSTERED ([RowID] ASC) ON [PRIMARY]) ON [PRIMARY] GO ALTER TABLE [etl].[SSISErrorHandlingLog] ADD CONSTRAINT [DF_SSISErrorHandlingLog_InsertedDateTime] DEFAULT (getdate()) FOR [InsertedDateTime] GO
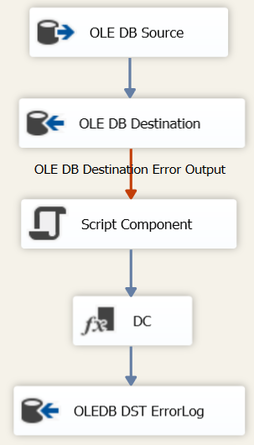
Additional derived columns might be as shown below: (I did not do myself any favors by making my table's string data types VARCHAR() instead of NVARCHAR(), so please follow your own DB data type standards.)  If you are redirecting error from multiple places, like both your SRC and DST, use a Union All task before the script task making sure to only include needed columns -- you may get SSIS error when trying to union large string values, so only union needed PKs, FKs and BKs consumed by the RowData expression. IMPORTANT: All things in moderation! Here is an error handling example of what NOT to do.  Where Things Go Wrong:
Conclusion: There is more than one way to trap and report SSIS errors, but in the end, we are all traditionally using a package event handler or redirecting errors in the data flow. I like to see the data that caused the problem, so I tend to go a little overboard with the information concatenated for the etl.SSISErrorHandlingLog.RowData column. I also hook up my error table to a SSRS report and SSRS subscription in an effort to actually act on the data collected, not just store it. I always "knew" that ADO.NET was slower than OLE DB destination SSIS components, but I had never tested it. This month I was testing a 3rd party SSIS destination component that had been built on ADO.NET and, oh my (!!). The performance was substantially slower than what I could get done with a traditional OLE DB upsert process. However, before I told the client, "Abandon ship! Every SSIS package for itself!", I decided to try a few simple tests. Here are my results of my second test, an upsert (insert new rows and update existing rows): Environment
Test: Insert and Bulk Update, or Merge() Setup: 6,121,637 rows were removed from dbo.DestinationTable prior to each test. Consequently, these tests inserted 6,121,637 rows and updated 6,121,638 existing rows. Results: 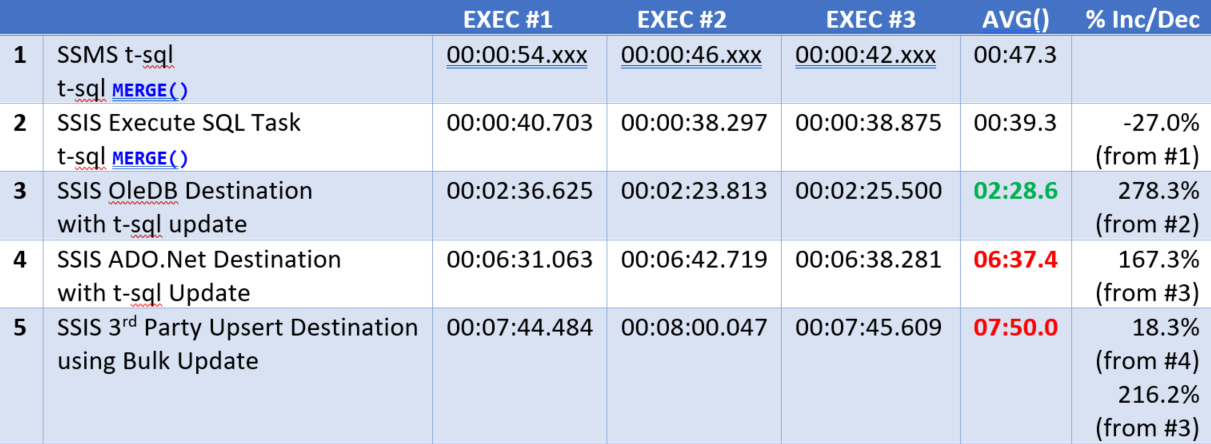 1. This was a typical t-sql MERGE() statement with no DELETE and no output into a result table.
2. The same MERGE() statement executed through SSMS in #1, was executed through a SSIS Execute Sql task 3. An old-fashioned OLE DB upsert process: If key found, insert to DestinationTableForUpdate, if new, insert into DestinationTable. An execute Sql task followed the data flow to UPDATE DestinationTable with values found in DestinationTableForUpdate. 4. Rinse and repeat #3 using ADO.NET components 5. Third party upsert component which handles the insert and update in one beautiful simple ... easy ... low maintenance ... any-entry-level-SSIS-developer-can-do-it task. (I really wanted to use this SSIS add-in!) Conclusion: OLE DB has better performance, and because the nifty 3rd upsert task is built on ADO.NET, I won't be using it nor recommending it for use in anything other than a small to mid-size company with small MB incremental loads. Bummer! The good news is that I now have a benchmark and if Microsoft improves ADO.NET in future releases on SQL Server, I'll be pulling out my POC database and hoping for better results. (p.s. If you are wondering why I will not recommend sacrificing the permanent daily ETL load on the alter of an immediate faster ETL development, please see my BI Wheel. ETL is not the center of the wheel.) 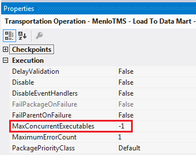 Microsoft has built in multiple data flow performance features that you can read about here (http://msdn.microsoft.com/en-us/library/ms141031.aspx). The following list is not all-inclusive, but the following best practices will help you to avoid the majority of common SSIS oversights and mistakes. 1. Give your SSIS process its own server. The resources needed for data integration, primary memory and lots of it, are different than for data storage. Granted, if your entire ETL process runs in just a few hours during the night when no end users are connecting, the case can be made to share servers; however, more often, real-time requirements and on-demand transformation are reasons to give your ETL process dedicated hardware. 2. Only update rows in your data warehouse that have been changed or deleted from your source system(s).
3. Install and test for adequate RAM on the SSIS server. Sorting 2TB of data requires 2TB of RAM, and SSIS will start to write the data to disc when all available memory is taken. As part of your Test / QA methodology, you should use Performance Monitor and have your network team notify you whenever Buffers Spooled goes above zero or Avg. Disk sec/Transfer gets above 10. Test and monitor the following PerfMon counters.
4. Take note of your MaxConcurrentExecutables package property. This defines how many tasks can run simultaneously. The default value is negative one (-1), which means the number of physical or logical processors plus two (2) is the number of control flow items that can be executed in parallel. It is generally recommended that you leave this setting at the default unless you are absolutely sure that parallelism is causing an issue. 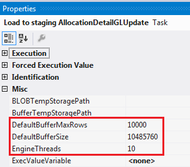 5. Adequately test and update data flow properties that impact performance.
1. A good SSIS package design will be repeatable. If you find yourself adding new tasks and data flow exceptions to your packages, you need to stop and reevaluate the original layout. One SSIS project will have several “templates” that are reused without a single design change for the life of the data warehouse. You should only have one or two template variations for each of these areas:
2. Plan for restartability. As of SQL 2014, SSIS checkpoint files still did not work with sequence containers. (The whole sequence container will restart including successfully completed tasks.) The solution is to build Restartability into your ABC framework. 3. Verify your ETL process. Just because your ETL finished without error – or you successfully handled your errors, doesn’t necessarily mean the SUM() of SourceSystemNet equals the SUM() of SSAScubeNet. Use your verification process this way. a. It should be the final step of your ETL / ELT process b. It should confirm that strategic SUM() and row COUNT() are accurate c. It should report on dropped rows discarded during the ETL from an INNER JOIN or WHERE clause d. It should automatically send emails of errors that have been allowed to “report and pass”. 4. Collect Metadata! Audit, balance and control (ABC) should be planned for and implemented from the very first day. You should store this ABC data in a separate SQL Server database, and at any point in time be able to determine the following:
5. Trap for Errors both through On Error events and through precedence constraints. There are two types of errors to successfully handle in an ETL / ELT process
For a full list of MS BI Best practices, download the following file:
|
|||||||||
| Microsoft Data & AI | SQL Server Integration Services |
 RSS Feed
RSS Feed
