SSIS 2016, An efficient way to mark deleted source system rows in a persisted data warehouse table8/23/2017 Even though many people think data warehouses ETLs (extract, transform and load) should contain insert data flows only, the vast majority of people I work with also have to deal with updates. Many have to also handle marking data warehouse rows as IsDeleted = "Y" in their ODS and EDW data repositories. If you are working with a dimension tables with less than 500K rows (an estimate), a traditional lookup task might work just fine. The data flow would look like this: 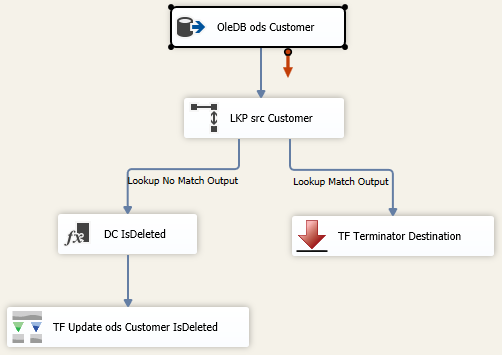 (TF = Task Factory. This is a great SSIS add-in for a nominal cost available from Pragmatic Works.) The problem with the above methodology is that although it may work, it is not efficient. I am a firm believer in performance tuning SSIS packages attempting to shave off minutes, and often seconds. Consequently, just because we get a green check mark, that is NOT indicative of “all is well”. In the above data flow, every ods.Customer has to be looked up in the src.Customer table. P-a-i-n-f-u-l! As with everything SSIS, there are multiple ways to get the same data flow accomplished, and I tip my hat to those of you who like to write C#. In my experience, C# seems to be able to complete a data flow task faster than many comparable SSIS components, but C# is not my go-to solution. An entry-level developer will probably be maintaining and enhancing the package, so I try to find an alternative. Keeping with OOP (object oriented programming) techniques, I tested two alternative options this week that I thought were worth a share.
Working with a dimension table containing 5 million rows (it was “people” and there really were that many people so there was no trimming down the dimension row count), MergeJoin took 3 minutes. The standard lookup took over 20 minutes. Assumptions:
MergeJoin Solution: It isn’t that complex. Add two OleDB source tasks to a data flow: one for your actual source that is deleting records (and in my opinion, behaving badly, but sometimes that just cannot be helped) and a second source component for the data warehouse. Use a MergeJoin to bring the two together, use a conditional split to send (now) missing PKs to an upsert or stage destination. I like to use TF (Task Factory’s) Upsert component as it is super easy to configure. A MergeJoin solution for marking data warehouse records as deleted in the source will look something like this: 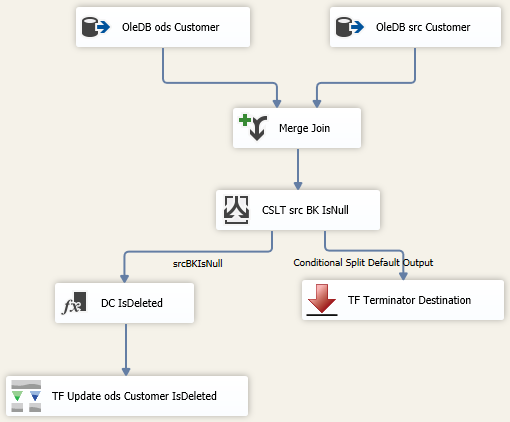 Key to performance success in the above data flow is sorting both the ods.Customer and src.Customer tables including setting the sort properties of the Advanced Editor. Right mouse click on the OleDB source task --> Show Advanced Editor --> Input and Output Properties tab --> Ole DB Source Output --> IsSorted property = True. On this same tab click on Ole DB Source Output --> Output Columns --> [Your Business Key Column Name]--> SortKeyPosition = 1 For those new to SSIS, the Merge Join and Conditional Split components are pictured below to fill in the blanks of the MergeJoin data flow.
Temp Table Solution: I won’t spend too much time here because this option was a bit slower than the MergeJoin, and requires a stage table in the same database as the ODS. The basic concept is to stage the unique BKs (business keys) of the source into your ODS database using a TRUNCATE and full reINSERT. Then perform the lookup between your ODS database and the newly loaded stage table. This does work, and avoids a lookup to a 2nd server or source, but it is not my personal preference. A temp table solution (stg.Customer) will look something like this: 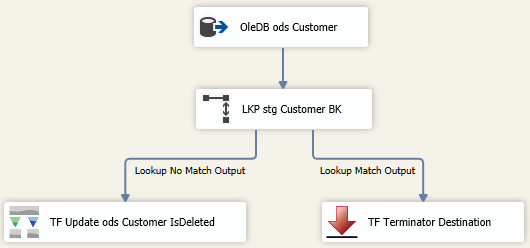 Conclusion: We might not like it, but sometimes we must make a full comparison between our incrementally loaded data warehouse table and a source system to find business keys that no longer exist in the source. SSIS is built to handle this, but we still need to try several options to find the best performing solutions for our unique environments.
This blog post just dealt with the ODS; deleted source records still have to be handled in the EDW. I loath seeing IsDeleted columns in true data warehouses. Is there a reporting requirement for deleted records? Are you going to put an index on that column? Will you have two sets of views, one with deleted records and one without? A much better way to handle deleted source records already persisted to an EDW is to create a DEL (deleted) schema and move the edw.Customer rows to del.Customer. It takes more ETL effort, but once developed, always done. ROI (return on investment) is not having to wade through deleted rows in the EDW. I feel another blog post coming ...
2 Comments
D B
2/16/2021 01:47:09 pm
This was just what I needed. Using a merge join, I am able to detect deletes on a table of 30 million rows in about 15 seconds. Not bad!!
Call Girls in Ghaziabad Leave a Reply. |
| Microsoft Data & AI | SQL Server Integration Services |
 RSS Feed
RSS Feed
