|
I have a PPTX slide that I use when speaking about data modeling for BI. (You can find my Pragmatic Works webinar here.) The slide is OLTP vs OLAP and is an 10K foot view of an actual denormalized ERD. 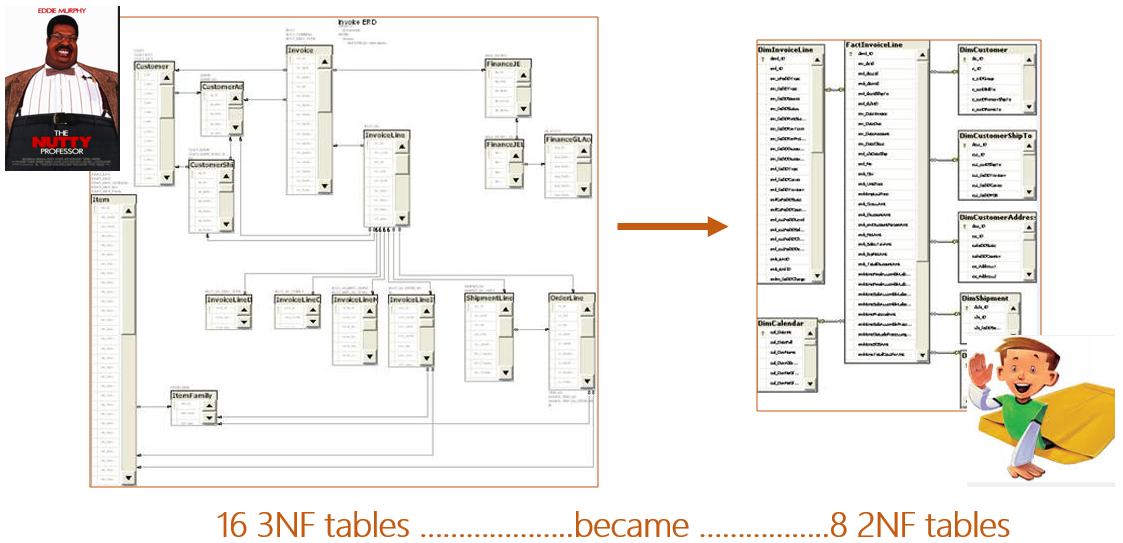 I'm sharing the above slide for those that are new to denormalization, but I think more can be said about how to handle dimensions that "snowflake" or daisy chain to each other. You can see this happen in AdventureWorks between the Product, ProductSubCategory and ProductCategory tables. When life is simple and all fact tables relate to Product on ProductKey, denormalization is easy to model. Option #1: Combine the parent and child tables into a single subject area dimension. 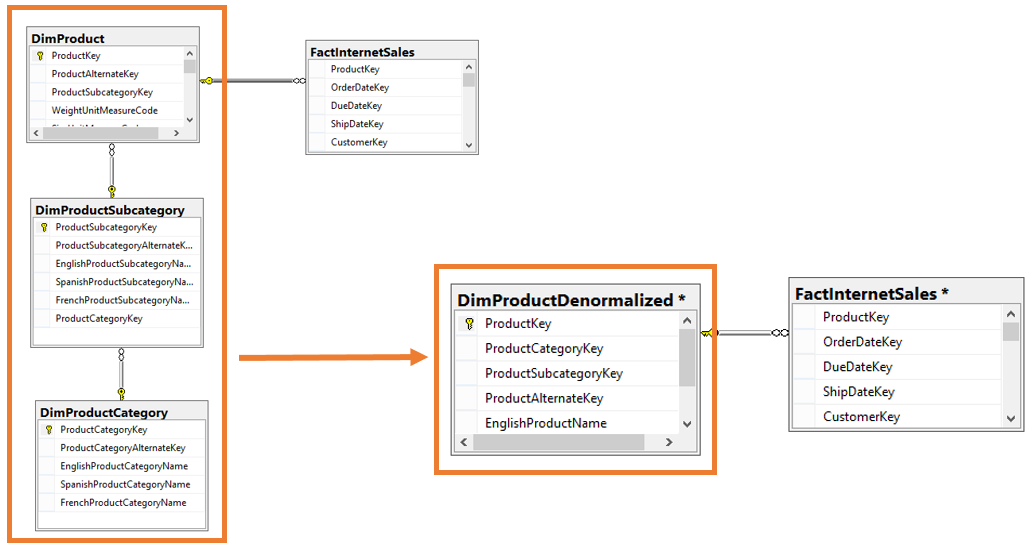 In the above solution, all three product tables were joined together into a single DimProductDenormalized. The new table contains columns and keys from all three original tables. This works well until a second fact table does not have a ProductKey, but only a ProductSubcategorykey. Now we are in a bit of a fix. 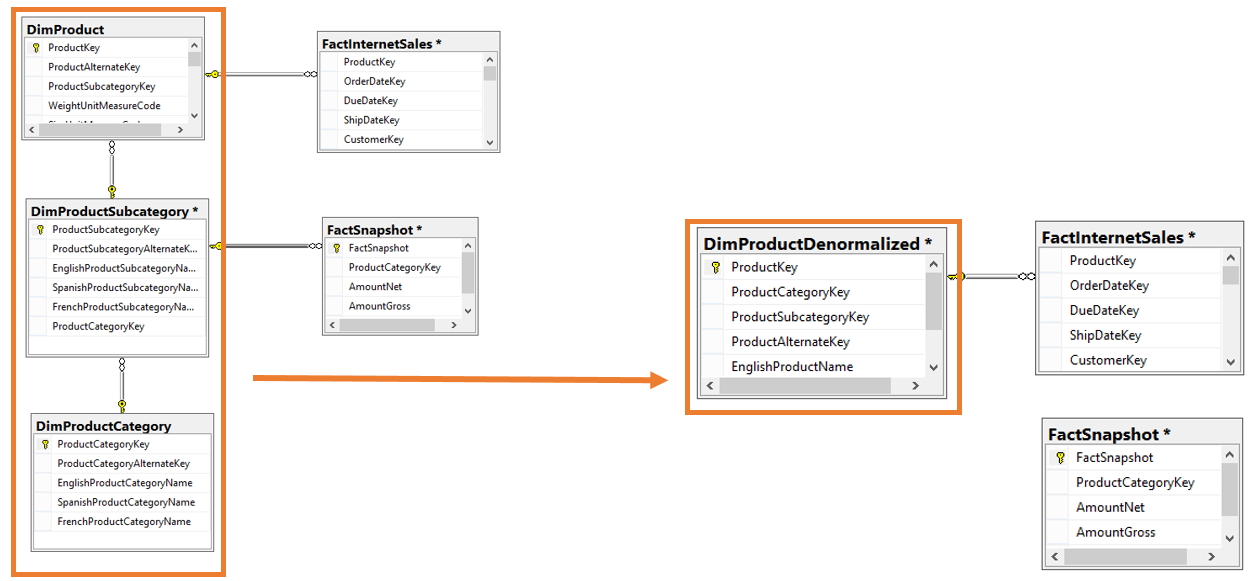 1. SSAS multidimensional cubes are designed to effectively and efficiently handle this exact scenario through attribute and cube relationships. 2. SSAS tabular models will require a second dimension at the higher, product category, grain. 3. The SQL database does not support a relationship between the denormalized DIM and the FactSnapshot and in fact will throw a "The columns in table ‘DimProductDenormalized’ do not match an existing primary key or UNIQUE constraint" error. For me, this is not an issue as I only keep SQL-defined table relationships in a data warehouse for the first year as a second measure of protection for the ETL which should be enforcing referential integrity anyway. 4. By combining small dimensions into a single subject area dimension, dimension count in the semantic layer has decreased and natural hierarchies are now available. Key Takeaway: The above scenario only works well for small code + description tables that can be combined to form a subject area dimension. Option #2: Pull the individual dimension keys into the fact table whereby removing the dimension snowflake and creating a star schema around each fact table. 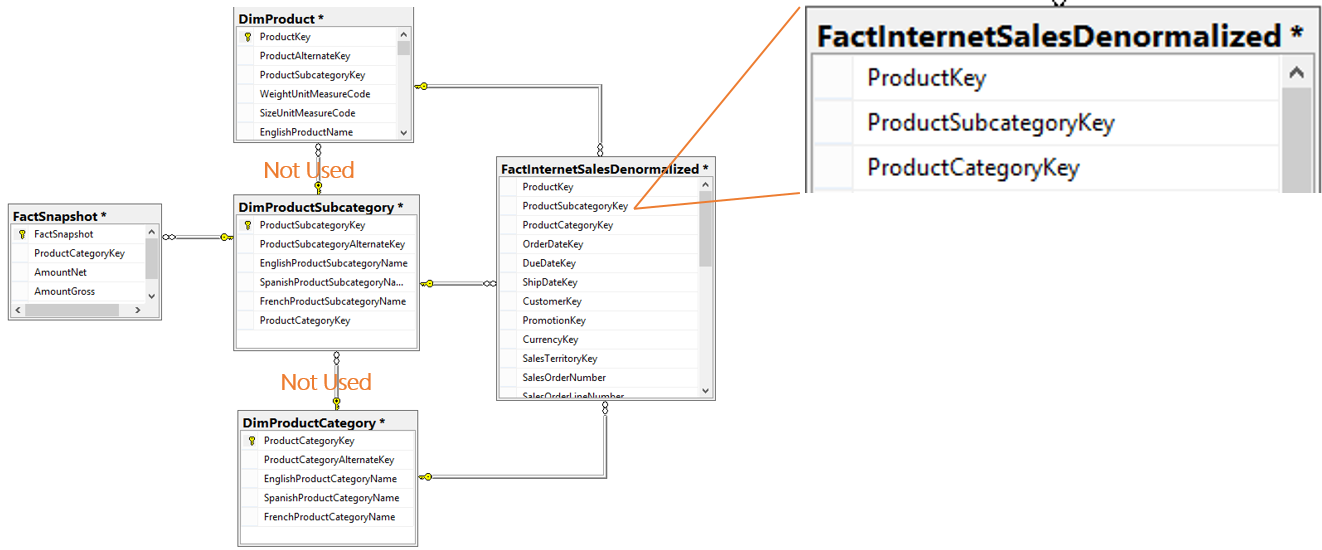 1. Snowflaked relationships are no longer used although they can still exist on disc. 2. Fact tables of different grains both have a true star schema 3. Dimension count in SSAS has increased. 4. "Subject area dimension" advantage of option #1 is lost. Leaving the Land of AdventureWorks How might we implement these ideas in a more complex scenario? What happens when each snowflaked dimension is already a subject area dimension and contains ten, twenty or more dimension attributes? Please allow me to jump over to Visio now and bring in a conceptual diagram. 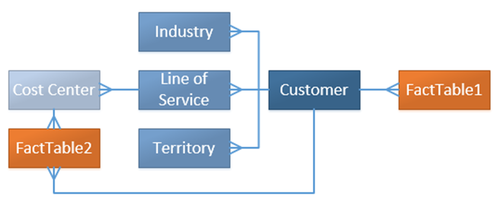 1. Multidimensional cubes handle 3NF through dimension design and referenced cube relationships. All is well. 2. Tabular models can consume 3NF by default design. 3. SSAS, SSRS and Power BI can all handle this ERD effectively. Changing this data model is not a requirement for a data warehouse design. In fact, this is what I think of as a Bill Inmon, the official father of data warehousing, design. 4. If you are familiar with my BI Blueprint, you will usually find this data warehouse design in column 5. 5. This data model is NOT optimized for reporting, but is CAN WORK just fine. Significant Issue: Type 2 SCD (slowly changing dimensions) can explode row counts if perpetuated down all referenced relationships. For example, when type2 DimCostCenter has a change and inserts a new row, DimLineOfService has to react and insert a new row as does DimCustomer. Regardless of 2NF, 3NF or worst normal form, type 2 data warehouse model with layers of parents and grandparent dimension tables will have this problem. This needs its own blog post. Staying focused on snowflaking dimensions ... Option #2 solution shown with larger dimensions that cannot be combined. 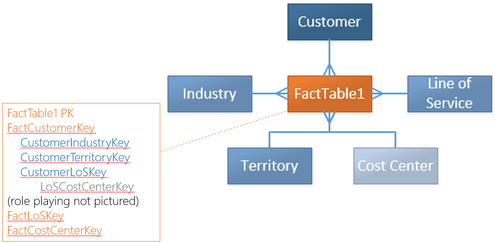 1. Just like the AdventureWorks star schema, this is the same concept and gives exceptional query performance because this design is optimized for reporting. 2. The dim-to-dim relationships still exist, although not pictured, and are used only for ETL. 3. Very Kimball-ish FK (foreign key) heavy fact tables 4. Key Concept: Parent and grandparent dimension FKs are brought into the fact table -- including the many role playing dimension keys that may exist in one or more dimension layers FactTable,CustomerIndustry1Key FactTable.CustomerIndustry2Key FactTable.CustomerIndustry3Key 5. Be sure to prefix your role playing dimension keys or the cost center associated with the transaction will get confused for the default cost center associated with the customer. 6. In my BI Blueprint, you will find this data warehouse design in column 7. 7. Type 2 SCD challenges still exist 8. This is a good idea (and my personal preference) but everyone IS NOT DOING IT and there are very effective 3NF data warehouses that function daily. For a company that has an extraordinary amount of snowflaking dimensions or strict (or unknown) type 2 requirements, this star schema may become a disadvantage.
0 Comments
Leave a Reply. |
 RSS Feed
RSS Feed

