|
To prove out SQL Server’s columnstore capabilities, I wanted to set up my own POC (proof of concept). I found, however, that to do this, I needed a more fundamental understanding of how and when SQL Server actually took advantage of the benefits of columnstore. So having worked through this for myself, I thought I’d document my Columnstore POC for you. The purpose of the article is to help you setup your own POC so you can test this out for yourself with your own data – the intent is not to explain columnstore in general. First, to setup your POC, make sure your data store and t-SQL meet these qualifications: 1. Have at least one FACT table with at least 100 million rows. I setup the following: a. Four fact tables with identical values with 100.2 million rows each § A heap table with no indexes or keys – created for the sake of example § An indexed table with a clustered PK, but no columnstore – a common SQL 2008 R2 data warehouse scenario § A non-clustered columnstore indexed table which included all columns – a SQL 2012 scenario § A clustered columnstore indexed table which included all columns – a SQL 2014 scenario b. One degenerate dimension table containing a clustered PK. This table had a 1-1 relationship with my fact table. c. Two dimension tables containing a clustered PK, one being a date or calendar table. In the end, my table list was as follows … 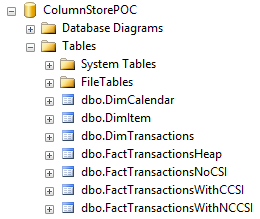 NoCSI = No clustered columnstore index (clustered PK) WithCCSI = With clustered columnstore index (no PK) WithNCCSI = With non-clustered columnstore index (no PK) … and my indexes were as follows: 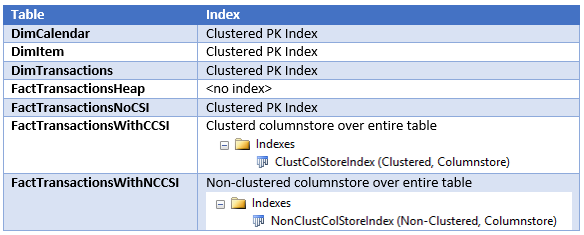 2. Understand that a clustered Columnstore index is the primary storage for the entire table. A nonclustered Columnstore (NCCS) index is a secondary index. A table with a NCCS is actually a rowstore table and the index is a copy of the rows and columns in the table. 3. Model your POC in a proper star schema using integer data types for PKs and SKs etc. 4. To test Columnstore, your t-sql must use an aggregate, like SUM() or COUNT(), a GROUP BY and preferably an ORDER BY 5. To test segment elimination, use a WHERE clause that will pull back only a subset of data 6. To take advantage of batch mode query processing, your t-SQL should use INNER JOINS, not LEFT OUTER or OUTER joins. This was true in SQL Server 2012. I could not replicate the ‘Row’ Actual Execution Mode in SQL Server 2014. 7. This might seem obvious, but make sure you are working in the SQL server 2014 version of SSMS (SQL Server Management Studio). You can actually create a clustered Columnstore index in SQL 2012 SSMS on a table stored on a SQL 2014 instance, but it just gets confusing because the SQL 2012 GUI won’t visually indicate it. When you think you are ready to go, double check your table design and data by running some system views. 1. Verify that Columnstore indexes really exist. SELECT distinct t.name FROM sys.column_store_row_groups csrg LEFT JOIN sys.tables t on csrg.object_id = t.object_id  2. Verify that your fact tables contain the same number of rows. You can do this a couple of ways. a. Script to select table metadata SELECT tbl_ObjectID = t.object_id ,tbl_SchemaName = s.name ,tbl_TableName = t.name ,tbl_TableType = t.type ,tbl_TableTypeDescr = t.type_desc ,tbl_DateCreated = create_date ,tbl_RowCount = si.rowcnt ,tbl_ColumnCount = c.ColumnCount FROM sys.tables t WITH (NOLOCK) LEFT JOIN sys.schemas s WITH (NOLOCK) on t.schema_id = s.schema_id LEFT JOIN sys.sysindexes si WITH (NOLOCK) on t.object_id = si.id AND si.indid < 2 LEFT JOIN (SELECT object_id, COUNT(*) as ColumnCount from sys.columns c group by c.object_id) c on t.object_id = c.object_id b. Script to get space used exec sp_spaceused '[dbo].[FactTransactionsHeap]', true; exec sp_spaceused '[dbo].[FactTransactionsNoCSI]', true; exec sp_spaceused '[dbo].[FactTransactionsWithCCSI]', true; exec sp_spaceused '[dbo].[FactTransactionsWithNCCSI]', true; Before we start testing for query performance, also take a look at the space used. It should come as no surprise that the clustered columnstore table uses 32% less space than the other tables. 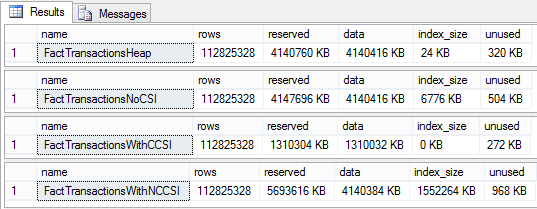 You can read about sp_spaceused on MSDN here (https://msdn.microsoft.com/en-us/library/ms188776.aspx), but a brief explanation is as follows: · Reserved is the total amount of space allocated by objects in the database · Data is the total amount of space used by data · Index_size is the total amount of space used by index · Unused is the total amount of space reserved for objects in the database, but not yet used. Nicely formatted, our test data looks like this: 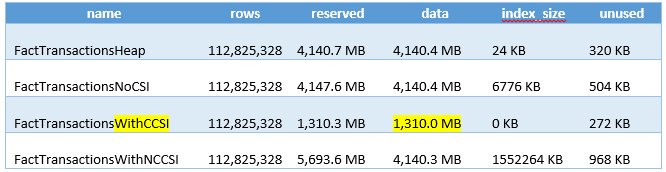 Now for the good stuff! Let’s write a typical OLAP query and run it against each fact table recording execution times. SET STATISTICS TIME ON GO SELECT c.cal_Year ,i.itm_Code ,SUM(trn_NetAmt) as SumOfNetAmt FROM dbo.FactTransactionsHeap t --dbo.FactTransactionsNoCSI t --dbo.FactTransactionsWithCCSI t --dbo.FactTransactionsWithNCCSI t INNER JOIN dbo.DimCalendar c on t.trn_TransDateSK = c.cal_DateIntPK INNER JOIN dbo.DimITem i on t.trn_ItemSK = i.itm_PK GROUP BY c.cal_Year, i.itm_Code ORDER BY i.itm_Code, c.cal_Year Returning 177,099 aggregated rows, these were my execution times:  Before moving on to add a WHERE clause, let’s take a look at our query execution plans. As expected, our heap table used a table scan. 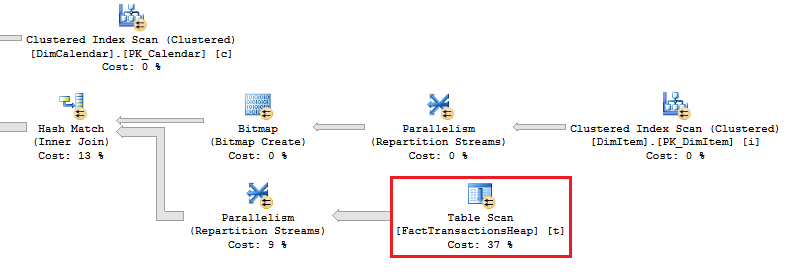 Our table with only a clustered PK (our SQL 2008 R2 scenario) used a clustered index scan. 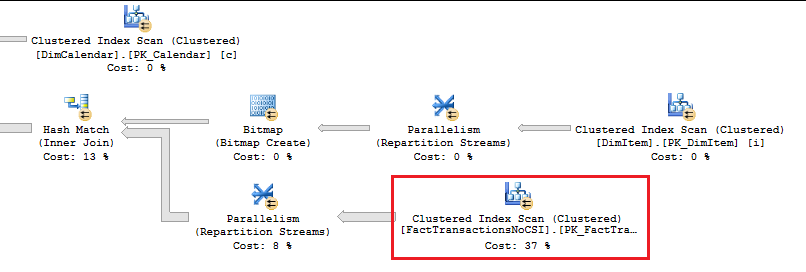 Our table with a non-clustered Columnstore index (our SQL 2012 scenario) used a Columnstore index scan. 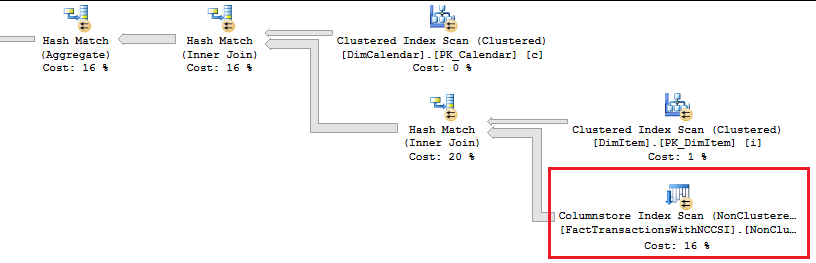 We have almost identical results with our clustered Columnstore indexed table (our SQL 2014 scenario). 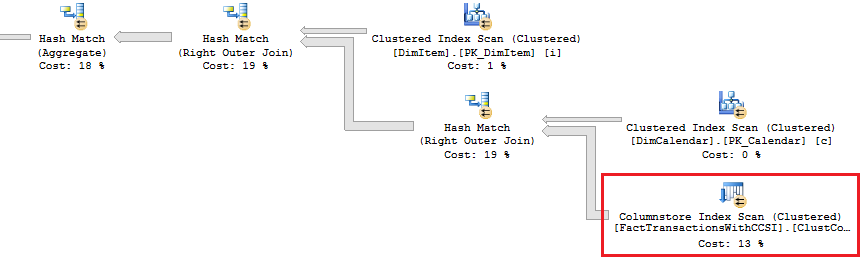 Let’s take this one step further. Hover your mouse over your Columnstore Index Scan operator. If your query is optimized, your Actual Execution Mode should say ‘Batch’. 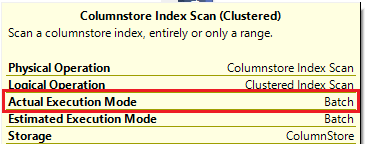 This is a fundamental principle of query performance. You want SQL Server to use ‘Batch’ mode vs ‘Row’ mode as much as possible. If you look under your Heap or NoCSI scan operators, you will see that they are using a ‘Row’ Actual Execution Mode … and therefore they take longer to execute. Okay, now let’s add a WHERE clause as 99% of the OLAP queries I have seen want to filter or slice on some sort of date value. We should also talk about segment elimination, which you can read up from TechNet here --> (http://social.technet.microsoft.com/wiki/contents/articles/5651.understanding-segment-elimination.aspx). The short version is SQL Server segments columnstore columns in groups of roughly 1 million rows. Metadata associated with each segment exposes a MAX and MIN value of each segment. So when you filter on DimDate.DateKey between [x] and [y], SQL Server will look at the segment metadata and automatically skip past those segments that do not contain qualifying column values. An example of how to verify columnstore segment elimination can be found here --> (http://social.technet.microsoft.com/wiki/contents/articles/5611.verifying-Columnstore-segment-elimination.aspx) but for our purposes, let’s have an element of trust and look at our execution results from a filtered query. First, let’s take a look to see what we have to work with. 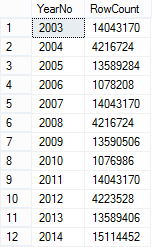 Next, let’s build a query. SELECT c.cal_Year ,i.itm_Code ,SUM(trn_NetAmt) as SumOfNetAmt FROM --dbo.FactTransactionsHeap t --dbo.FactTransactionsNoCSI t dbo.FactTransactionsWithCCSI t --dbo.FactTransactionsWithNCCSI t INNER JOIN dbo.DimCalendar c on t.trn_TransDateSK = c.cal_DateIntPK INNER JOIN dbo.DimITem i on t.trn_ItemSK = i.itm_PK WHERE t.trn_TransDateSK Between 20060101 and 20121231 GROUP BY c.cal_Year, i.itm_Code ORDER BY i.itm_Code, c.cal_Year Returning 93,469 aggregated rows, these were my execution times:  A quick note about our ‘Heap’ table and the ‘NoCSI’ table which contained a clustered primary key. How many times have you heard the phrase “index lite”? We have a clustered PK on our FactTransactionsNoCSI and our one-to-one degenerate dimension DimTransactions to support that relationship, but notice how the ‘Heap’ table actually had better query performance. It is only fair that we take a minute to demo a couple of anti-performance practices given to TechNet’s SQL Server Columnstore Performance Tuning article found here --> (http://social.technet.microsoft.com/wiki/contents/articles/4995.sql-server-Columnstore-performance-tuning.aspx) 1. String Filters 2. OUTER JOINS 3. Joining to an equally large DegenerateDim table that does not have a columnstore index Here is our t-SQL where we are just wanting OPEN status transactions SELECT c.cal_Year ,i.itm_Code ,SUM(trn_NetAmt) as SumOfNetAmt FROM dbo.FactTransactionsWithCCSI t INNER JOIN dbo.DimCalendar c on t.trn_TransDateSK = c.cal_DateIntPK INNER JOIN dbo.DimITem i on t.trn_ItemSK = i.itm_PK INNER JOIN dbo.DimTransactions dt on t.trn_PK = dt.trn_PK WHERE t.trn_TransDateSK Between 20060101 and 20121231 and dt.trn_StatusCode <> 'CLOSED' GROUP BY c.cal_Year, i.itm_Code ORDER BY i.itm_Code, c.cal_Year Here is our query execution plan where our filter cost is 86% of our total execution time. Note the ‘Row’ Actual Execution Mode. 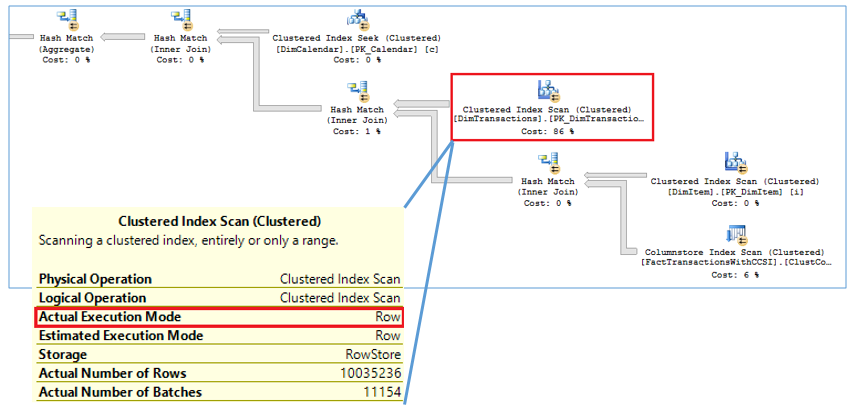 The case can be made that this is expected behavior and not the fault of our fact table columnstore index, and that is correct as we are filtering on DimTransactions which does not have a columnstore. Let’s put a columnstore index on DimTransaction as it does have as many rows as our fact table, and see what happens. CREATE TABLE [dbo].[DimTransactionsWithCCSI]( [trn_PK] [int] NOT NULL, [trn_No] [int] NOT NULL, [trn_SeqNo] [int] NOT NULL, [trn_SourceCode] [varchar](50) NOT NULL, [trn_RouteCode] [varchar](50) NULL, [trn_StatusCode] [varchar](50) NULL, ) ON [PRIMARY] GO insert dbo.DimTransactionsWithCCSI select * from dbo.DimTransactions create clustered Columnstore index dtClustColStoreIndex ON dbo.DimTransactionsWithCCSI go SELECT c.cal_Year ,i.itm_Code ,SUM(trn_NetAmt) as SumOfNetAmt FROM dbo.FactTransactionsWithCCSI t INNER JOIN dbo.DimCalendar c on t.trn_TransDateSK = c.cal_DateIntPK INNER JOIN dbo.DimITem i on t.trn_ItemSK = i.itm_PK INNER JOIN dbo.DimTransactionsWithCCSI dt on t.trn_PK = dt.trn_PK WHERE t.trn_TransDateSK Between 20060101 and 20121231 and dt.trn_StatusCode <> 'CLOSED' GROUP BY c.cal_Year, i.itm_Code ORDER BY i.itm_Code, c.cal_Year The result is that DimTransaction now has a CCSI. Consequently, we now have a 'bach' Actual Execution Mode for DimTransaction vs 'Row' and our query is off and flying! 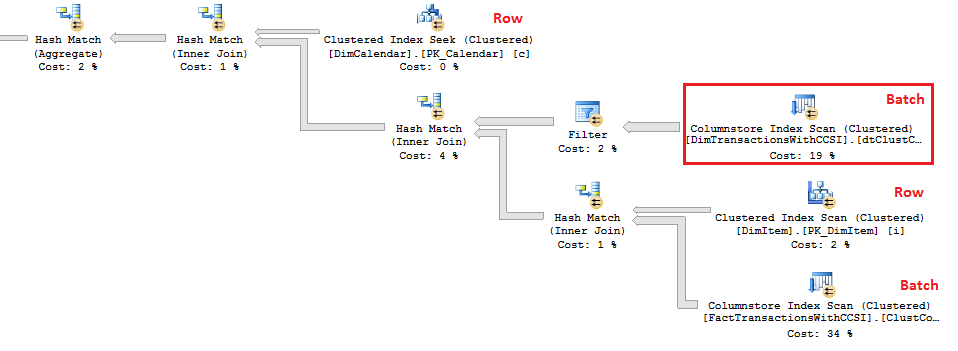 Change the INNER JOINS to LEFT OUTER JOINS. SELECT c.cal_Year ,i.itm_Code ,SUM(trn_NetAmt) as SumOfNetAmt FROM dbo.FactTransactionsWithCCSI t LEFT OUTER JOIN dbo.DimCalendar c on t.trn_TransDateSK = c.cal_DateIntPK LEFT OUTER JOIN dbo.DimITem i on t.trn_ItemSK = i.itm_PK LEFT OUTER JOIN dbo.DimTransactionsWithCCSI dt on t.trn_PK = dt.trn_PK WHERE t.trn_TransDateSK Between 20060101 and 20121231 and dt.trn_StatusCode <> 'CLOSED' GROUP BY c.cal_Year, i.itm_Code ORDER BY i.itm_Code, c.cal_Year The result in SQL 2014 is that my LEFT OUTER joins still used ‘batch’ Actual Execution Mode and SQL Server is even aware enough to turn the one-to-one relationship between DimTrans and FactTrans into an INNER join. 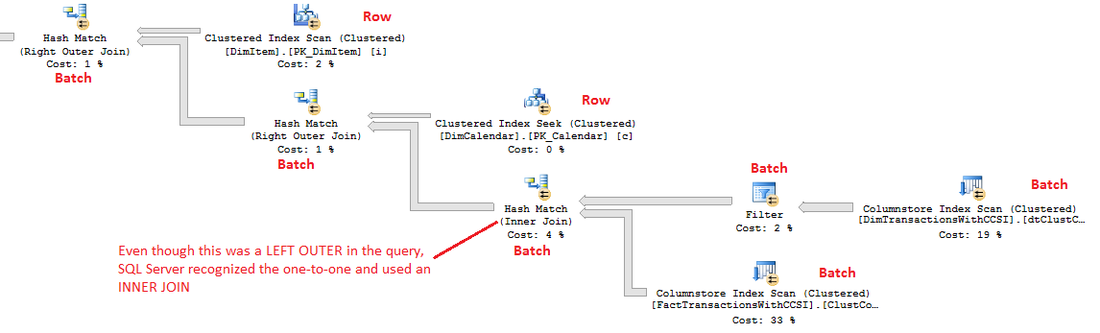 In summary,
1. With each new version of SQL Server, Columnstore is going to enhance, so do not assume that all prior guidelines and best practices remain the same. 2. Columnstore indexes do work and if you are running Enterprise edition, take advantage of them! 3. They are intended for OLAP environments primarily. 4. Executing “Select * FROM MyColumnstoreIndexedTable” will not show you the benefits. You have to aggregate some data, group, order and filter which is the exact scenario of data warehousing queries. 5. You’ll only see significant benefits of Columnstore when working with large data volumes. 6. Once again, Columnstore just like SSAS, will produce the best results when working with star schema data models. Please remember that the purpose of this documentation is not to explain columnstore, but to help you put together a POC and prove out the capabilities of columnstore indexes. A blog site that I feel goes above and beyond for columnstore documentation is Niko Neugebauer and can be found here (http://www.nikoport.com/Columnstore/). Niko’s site has 56 tips and tricks for columnstore. Enjoy!
1 Comment
1/31/2023 11:32:44 pm
Thanks for sharing this informative blog Leave a Reply. |
| Microsoft Data & AI | Database administration |
 RSS Feed
RSS Feed
